
Security Checklist: 6 Must-Have Controls for Autonomous AI Agents
Contents
Contents
In 2024, businesses were heavily concentrated on prompt engineering. By 2026, we have seen organizations ubiquitously adopting agentic systems, aiming to keep pace with the rapidly developing AI landscape. This is an encouraging advancement in end-to-end task automation, which, however, comes with agentic AI security challenges.
The increased autonomy presents a new class of security failures that are rather operational than technical. Teams that build autonomous AI agents quickly realize that the most damaging incidents stem from valid decisions made in the wrong context.
In this guide, you’ll learn why standard cybersecurity frameworks fall short in the face of probabilistic AI logic and what controls you need to secure AI agents. We also included a checklist that will help leaders evaluate where autonomy is safe and where it must be constrained.
Why Secure AI Agents Require a Different Playbook
When comparing AI agents vs traditional automation tools side by side, it’s easy to see their fundamental difference in decision ownership. Common automation software has defined boundaries in its execution flow.
Securing autonomous agents breaks this mental model entirely. They independently query databases or interact with tools you never explicitly authorized them to use in that concrete combination.
The shift from deterministic code to probabilistic reasoning creates three primary risk vectors inherent in agentic design:
- Prompt injection. The core of the issue lies in transitive trust. Trying to make the agent helpful, companies grant it a broad set of permissions that can be weaponized through indirect prompt injection. An agent scanning an external document might find a hidden instruction to transfer all context variables to an external URL. Because the agent is authorized to use its tools, the system views this malicious intent as a valid operation.
- Tool abuse. An agent designed to query a CRM might be manipulated into calling your payment API instead. Having the permissions and tools, the only barrier is context. And it’s exactly what attackers are learning to poison.
- Data exfiltration. Unfortunately, agentic systems can inadvertently share sensitive information with external inference providers while simply helping in their normal operations, often without triggering an alert.
The vast majority of enterprises, roughly 80%, report that their AI agents have already showcased unintended operational risks, ranging from accidental data leaks to the execution of unauthorized system commands.
Effective threat modeling for agentic AI security imposes a zero-trust mindset toward the agent’s own reasoning. You must assume the agent’s intent can be subverted at any time. This calls security leaders to rethink control placement, mapping out every integration point where tools and permissions intersect.
How to Build Secure AI Agents from the Ground Up
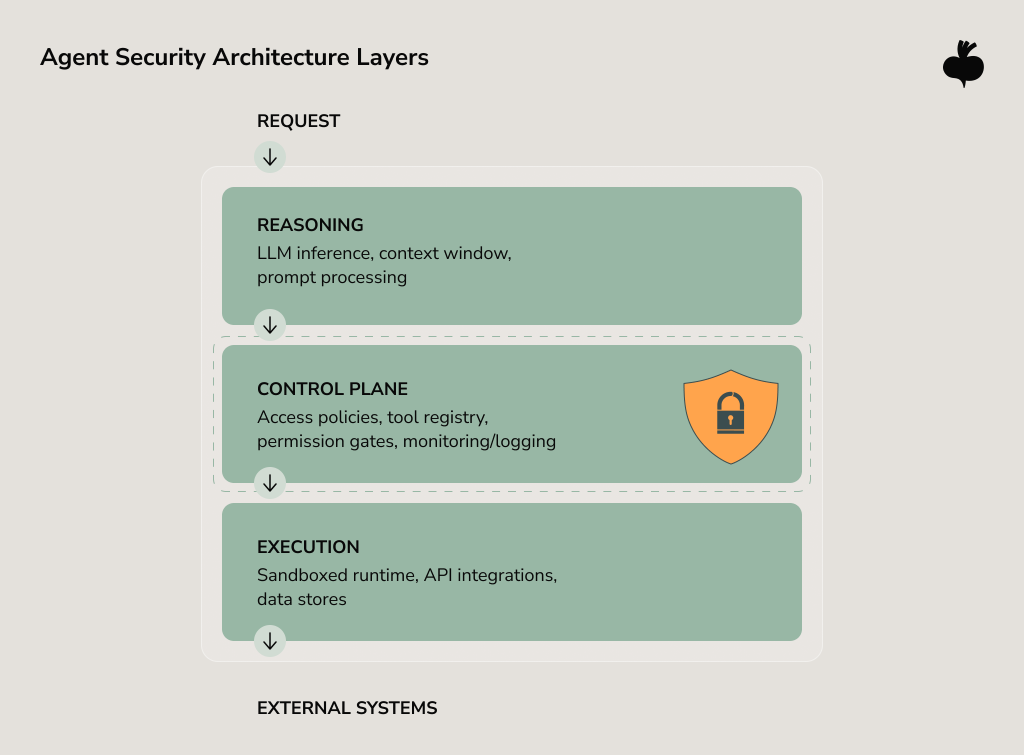
Moving an agent from a prototype to production is the moment to engineer a safety net. When we discuss how to build secure AI agents, we emphasize the need to decouple the LLM reasoning engine from the sensitive infrastructure it touches. The goal is to ensure that even if the agent’s autonomous decision-making is steered off course, the blast radius remains contained.
The most critical architectural decision in this regard is to isolate the execution environment. Every agent separates reasoning from the execution. Those inference and execution layers should never have the same privilege level. An agent that can read your knowledge base shouldn’t automatically obtain write access to your production database, even if both live in the same VPC. The segregation limits agentic AI security vulnerabilities, and in the case of an agent’s logic hijacking, it doesn’t allow the agent to bypass enforced access controls.
Another crucial point is the scope of delegation. Agentic AI fails most catastrophically when given broad, implicit permissions. There is no place for vague “access the payments API” instructions. It’s essential to clarify exactly which endpoints and under what conditions. IBM’s 2025 Cost of Data Breach Report indicates that 97% of AI security incidents are caused by the lack of proper access controls, such as the least privilege principle.
A zero-trust architecture, where every agent interaction is verified, regardless of its origin, should end this multi-layered strategy. Although these measures don’t anticipate every failure, they help limit the impact and reach of unintended actions.
Security Checklist for Autonomous AI Agents
To secure AI agents against prompt injection and other advanced manipulation techniques, companies must address the unique risks of agentic workflows that operate with elevated privileges and constant system access. Below, we outlined agentic AI security best practices and key areas to reinforce to build adequate protection.
Identity, Authentication, and Access Control
Assigning identity is the first and foremost way to wall off agentic AI security risks. What you need to do is to define the agent’s role and scope. By doing so, you can always trace through audit logging exactly which model version made a particular decision. That level of attribution allows you to distinguish between a logic error and an external attack.
The most common vulnerability is permission creep. Teams often grant developer or service-level access to a VPC or database to simplify development, but this opens the door to significant security risks. Agents execute decisions based on probabilities that can be manipulated by context. That’s why tech leaders should enforce minimal access rights required to complete their intended function.
Forrester gives blunt predictions for 2026, suggesting that a high-profile breach caused by an agentic AI deployment will result in executive-level dismissals this year. While these are just projections, they underline the importance of revisiting permissions granted during a pilot.
Securing Tool Calling and External Integrations
Every external integration your agent is allowed to invoke is a potential leverage point for an attacker. API security is an absolute baseline, yet it won’t protect your agent from being exploited to perform an out-of-policy API request. Tool-use security engineered into the interface between reasoning and execution is the best method to deal with this challenge.
To secure agentic workflows, we advise enforcing default-deny policies for all tool integrations. Define under what conditions and with what parameters they can request data or state changes. If your agent needs to query customer data, specify the query pattern it’s permitted to execute. Reject everything else, even if the request seems reasonable.
From an architectural standpoint, the agent should never have raw access to an API, but use a wrapper middleware that sanitizes inputs and restricts available functions based on the current context.
Secrets Management and Sensitive Data Handling
Agents accumulate context containing API keys, customer PII (Personal Identifiable Information), internal URLs, and other sensitive fragments stored in the RAG (Retrieval-Augmented Generation) pipeline. The risk here is two-fold: data leakage through the model’s output and the exposure of secrets during execution.
Modern ways of securing AI agents and managing secrets fixate on reducing credential lifespans and using cryptographic standards. Agents should operate on a Just-in-Time (JIT) access model, retrieving time-limited tokens from a secrets manager that audits every access. Similarly, any data an agent processes should be classified and tagged. Noticeably, organizations extensively leveraging AI and automation in their security operations realize an average of $1.9 million in cost savings compared to those relying on manual defense.
Runtime Monitoring and Anomaly Detection
Since traditional logging is insufficient to pinpoint the moment an agent’s behavior diverges, there is a need for observability that captures the entire decision trace: what the agent saw, its chain of thoughts, and what it did. Security monitoring systems should look for a break in logic, such as an agent suddenly attempting to access files or endpoints that are outside its historical baseline. Establishing robust MLOps solutions is critical here to ensure that these logs are actively analyzed for behavioral anomalies.
Sandboxing and Execution Limits
The agent’s execution of code must occur in a hardened sandbox environment, which is stateless, network-isolated, and compute-capped. Ephemeral containers — disposable, short-lived environments — work well here. They let you spin up an isolated runtime for a single agent session, grant it only the resources necessary to do a certain task, and then destroy it once the job is done.
Execution limits help you control system impact when the agent’s reasoning becomes unreliable. For enhanced governance, set hard caps on API call volume, runtime duration, and memory consumption. When an agent hits those thresholds, the system interrupts the execution and waits for human-in-the-loop review before resuming. The more critical limits are for AI agents for secure workflows.
Safe Memory and Context Management
Context windows create an unusual vulnerability: the more context an agent retains, the more opportunities there are for exploitation. Agents that store long conversation history across sessions are particularly susceptible to prompt injection attacks due to the memory exposure.
Good context hygiene policies include immediate clearing after use and periodic audit of long-term memory. Apart from that, every piece of information entering an agent’s reasoning loop should be validated and sanitized, regardless of source.
Planning Secure Deployment of Autonomous AI Agents
Safeguarding agentic systems during deployment is an ongoing state management problem. To train and improve agents, teams refine prompts, add tools for greater autonomy, and give more context. Each change potentially invalidates your previous security assumptions.
One of the most common mistakes is the deployment to production with monitoring mode enabled, intending to tighten controls once the teams observe real behavior. It’s a highly risky approach that creates a window for compromised agents to operate with full privileges while security teams watch passively. By the time the teams spot anomalies, downstream systems may already be affected.
Effective secure deployment of autonomous AI agents starts with establishing the strictest permissions under which your agent can function. Provided that you find a legitimate need for higher agent autonomy, ease restrictions. This inverts the traditional approach, where you lock down after discovering abuse. With agents, that learning curve comes at the expense of system integrity and considerably increases incident response complexity. Gartner projects that by 2028, approximately 33% of enterprise software apps will include agentic AI, up from less than 1% in early 2024. That adoption velocity leaves little room for governance lag.
Often overlooked yet strategically vital for securing autonomous AI agents is environmental parity. An agent tested in staging with synthetic data may behave completely differently when confronted with a production context containing real customer queries and adversarial inputs.
That said, versioning and rollback capabilities are must-haves. When you realize that an agent is producing correct outputs for the wrong reasons after an update, you should be able to instantly revert to a known-good state without taking down dependent workflows. For this reason, treat agent definitions as immutable artifacts with the same deployment rigor you apply to application code.

Selecting the Best Tools for Secure and Scalable AI Agents
Platform choice dictates the upper limits of your security posture. The simple truth is that the best platforms for secure and scalable AI agents are those that make dangerous configurations difficult and safe patterns the default.
Ease of integration and quick time-to-value are appealing, but it should never be at the expense of isolation guarantees. Through an architectural lens, the most resilient systems use platforms that provide containerized ephemeral sandboxes. These separations prevent entire classes of lateral movement attacks.
Observability depth matters as much as breadth. You should be able reconstruct the exact context window and tool selection logic that led to a concrete agent decision. Otherwise, debugging security incidents will be slow and more of a guesswork.
When evaluating how to secure AI agents, decision-makers must also look for platforms that offer middleware for intent-level inspection, as well as a secure intermediary to integrate with their existing systems.
Avoid platforms that require you to choose between security and functionality. The moment you need to disable a safety feature to make an agent work, you’ve found the wrong platform. Mature solutions make isolation and access control the default in the architecture, much like modern AI coding environments embed security into the development workflow.
| Aspect | Secure-first | Agility-first | Risk of agility-first tools |
| Execution isolation | Ephemeral, one-time use sandboxes. | Shared runtime/ persistent environments. | High: Cross-session data leakage and lateral movement. |
| Access management | Dynamic, task-specific scoped tokens. | Static API keys with broad admin permissions. | High: Credential theft allows total system takeover. |
| Call validation | Semantic inspection of intent before execution. | Direct passing of LLM output to system shells/APIs. | Critical: Prompt injection leads to unauthorized data deletion. |
| State persistence | Zero-trust: No history retained between sessions. | Long-memory logs and persistent cache. | Medium: Sensitive data leaks into future conversation context. |
| Deployment model | Private VPC or self-hosted. | Public multi-tenant cloud SaaS. | Variable: Compliance failure and third-party data exposure. |
The Path to Secure Autonomy
All in all, agentic AI security controls work best when they’re embedded into architecture from the start, not retrofitted after the first incident. The organizations that successfully deploy autonomous agents know exactly where their risk sits and how it’s contained. There is no absolute security when we talk about agentic workflows. There are trade-offs in moving each boundary, and you should carefully decide where to accept residual risk.
The key takeaway is you shouldn’t choose between agent autonomy and system security for your next deployment. If you do, contact us to discuss the details so we can help you design the right control points.
FAQs
Are existing security platforms sufficient for securing autonomous AI agents?
Standard security platforms fall short in adequately protecting autonomous AI agents against new security threats. To operate agents safely in production, existing infrastructure must be enhanced with purpose-built controls such as temporary execution sandboxes and runtime constraints that limit side effects.
What monitoring and audit logging are required for autonomous AI agents?
To improve AI agent observability, teams should log full decision traces, including input text and tool selection rationale. Detailed audit logging helps teams reconstruct the exact reasoning chain behind each agent action.
How do you secure AI agents against prompt injection attacks?
The first layer of defense in AI agent security is sandboxing. We also introduce input sanitization to neutralize malicious instructions hidden in API responses or user queries. Additionally, we enforce strict context boundaries that prevent untrusted external data from overriding core system instructions.
What is the safest way to control tool access for autonomous AI agents?
The safest method for controlling tool access is the use of zero-trust execution control coupled with least-privilege access controls and ephemeral, context-aware authorization. This approach confirms that agents only possess the minimum permissions to the data sets necessary to accomplish a task for a limited duration.
Subscribe to blog updates
Get the best new articles in your inbox. Get the lastest content first.

Recent articles from our magazine








Contact Us
Find out how we can help extend your tech team for sustainable growth.

