Contents
Contents
The most dangerous moment for a machine learning project is when it goes live. Success brings a surge in data volume and an immediate expectation of 99.9% uptime from stakeholders who have no interest in the technical mechanics.
For many decision-makers at the helm, that’s the moment when the dream of AI-driven growth hits the wall of operational reality, and the realization sets in that running a model is an engineering discipline. Indeed, MLOps services help teams manage the risk that emerges after launch and protect the bottom line as models begin to influence revenue and customer experience.
While high-profile MLOps examples in the real world, like Uber’s Michelangelo or Netflix’s Metaflow, use different approaches, the core lesson teams can take is that long-term ROI hinges on repeatable practices that survive the inevitable friction of scaling. Let us show you how this principle plays out across use cases.
Why MLOps Is Critical for Scaling Enterprise AI
There is a huge disconnect between a model that works in the lab and one that delivers sustained business value in production. Of 88% of organizations using AI, two-thirds are stuck in the pilot and experimentation phase. The blocker is lifecycle management. More often than not, models stall because teams can’t reproduce training runs six months later or because no one knows which data version produced which output. Rarely does performance degradation explain the delay.
MLOps addresses these blind spots by treating models as evolving systems and automating most of the overhead that accumulates after the deployment. By combining principles from machine learning, DevOps, and data engineering, MLOps enables four capabilities vital to keep AI reliable once it leaves the data scientist’s notebook:
- Reproducibility. Data and code versioning control enforced through MLOps allows teams to trace any prediction back to its source. Without this, debugging a production error becomes a days-long investigation into what happened rather than a fix for what broke.
- Drift-aware monitoring. If traditional CI/CD tracks only whether a system is up or down, MLOps adds model-specific validation and drift-aware monitoring to notice subtle changes in data patterns that degrade accuracy.
- Model governance. Scaling ML models increases the need for traceability and compliance. MLOps tracks every iteration of your model, giving your team the power to explain any decision or immediately roll back to a stable version if issues arise.
- Collaboration. Data scientists and DevOps teams work together within shared pipelines and tooling, which reduces handoff friction and ownership ambiguity, along with the risk of context loss.
MLOps examples from organizations running AI at scale show that the vast majority of the long-term work and risk reside in the operational lifecycle.
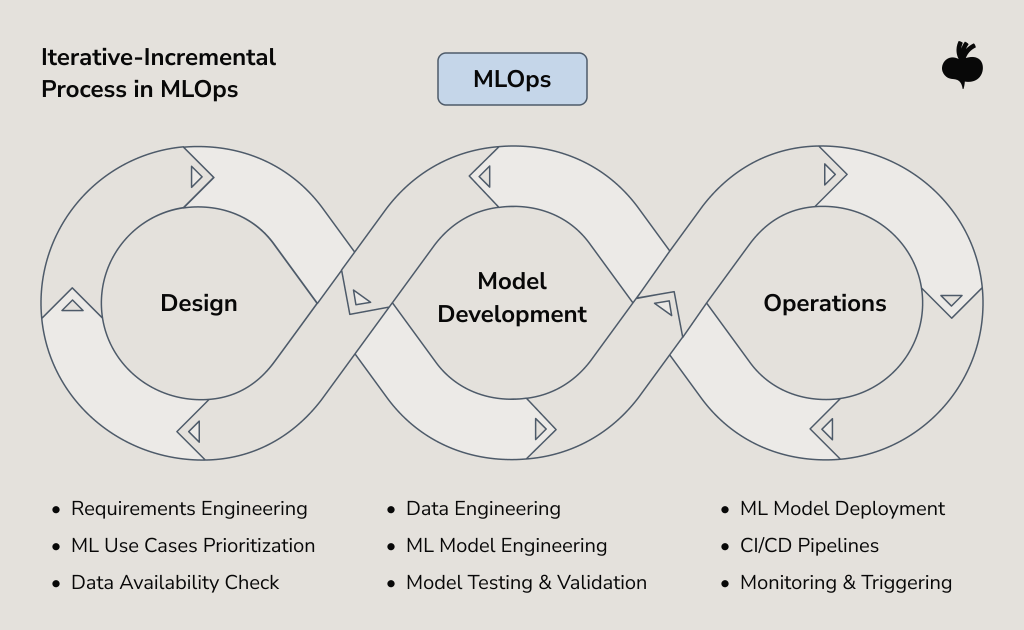
Industry-Specific MLOps Use Cases That Move AI From Promising to Profitable
Successful MLOps use cases tend to converge on a set of solution principles, namely CI/CD for ML, data versioning, model training, and automated retraining. What changes is the risk profile and where teams place their guardrails. Below, we walk through several MLOps examples to show how these principles are applied under different business constraints.
FinTech MLOps Example: Real-Time Fraud Detection
Financial fraud losses exceeded $12.5 billion in 2024, and bad actors now use AI to bypass static rule-based systems. Conventional, set-it-and-forget-it approaches to fraud detection can’t counter tactics that are becoming increasingly sophisticated at an unprecedented pace.
In production fraud detection, models analyze a number of transaction patterns, specifically geographic locations, purchase behavior, account activity against historical baselines, and more. Since new exploitation techniques emerge weekly, maintaining model accuracy is a significant challenge, especially when retraining is manual.
In this cat-and-mouse game with threat actors, MLOps, with its automated retraining pipelines that ingest new fraud signals and deploy updates without service interruption, is the most viable defense. Furthermore, model monitoring tracks decision latency, false-positive rates, and geographic coverage, in addition to model accuracy. When a model’s performance degrades, the system alerts engineers, while version control lets teams trace which dataset trained which model version during incident investigation.
Healthcare MLOps Use Case: Traceability in Predictive Diagnostics
Given the gravity of patient safety and the weight of regulatory mandates, healthcare AI model errors are unacceptable. That being said, predictive diagnostic models used to process medical imaging or patient records must show auditable behavior across diverse patient populations and provide explanations that clinicians and regulators can verify.
MLOps provides this auditability. Self-governing pipelines with built-in compliance apply policy controls at each lifecycle stage. Similarly, it’s indispensable for model drift detection, whether it’s a result of imaging equipment changes or treatment protocol adjustments. MLOps infrastructure helps teams meet regulatory expectations for traceability in clinical AI systems by monitoring for output ambiguity and retaining versioned records of every model decision.
This MLOps example underscores the importance of managing the full model lifecycle and shows a broader pattern seen in production healthcare ML: models that can’t be inspected can’t be trusted.
Retail MLOps Use Case: Demand Forecasting
Retailers deal with massive, fragmented datasets across thousands of SKUs (Stock Keeping Units) and regularly battle against model drift caused by seasonal trends or macroeconomic shifts that make yesterday’s patterns irrelevant.
To cope, leading teams deploy self-tuning predictive models segmented by product category. While this reduces manual planning overhead, the key challenge remains maintaining forecast precision for all those SKUs while at the same time adapting rapidly to abrupt market changes.
That’s the reason retailers turn to data pipeline development that integrates with MLOps pipelines for demand forecasting. Thus, they enable continuous, automated feeding of sales data and updating of training datasets on schedules that match business cycles. Using feature stores as a shared library of structured data suitable for ML ensures every forecasting model uses the same definitions for seasons and promotions. It solves the problem of inconsistencies that may appear when different teams accidentally build conflicting logic for the same business metrics.
Manufacturing MLOps Example: Defect Detection
Cloud-only ML is impractical for manufacturing because a model detecting defects on a high-speed assembly line cannot wait for a round-trip to a central cloud server. That’s a strong case for moving MLOps architecture patterns to the edge.
Manufacturing units deploy intelligence onto factory-floor hardware, including cameras and sensors, and use a centralized cloud-based control plane to manage them. When a camera spots a potential defect, the edge model classifies it instantly, triggering automatic rejection or flagging for human review. Meanwhile, edge devices stream only anomalous samples back to central systems, where data scientists retrain models to catch new defect types and deploy updates to all edge devices.
This hybrid edge-cloud setup introduces challenges that cloud MLOps often overlook, as it typically lacks the native last-mile connectivity to hardware necessary for industrial environments. Model version management across distributed hardware and consistent performance despite varying edge device capabilities are more difficult to achieve with cloud-native abstractions alone. Our data engineering-as-a-service teams build the scalable infrastructure needed to stream training data from edge locations back to the center and to orchestrate CI/CD for ML pipelines that push model updates to manufacturing sites globally.
Fighting Model Decay: A Core MLOps Use Case in Long-Term Operations
Model accuracy can degrade within days of deployment because production data diverges from the model’s training data. More than that, customer expectations increase, markets recalibrate, and fraud tactics become more intricate each day. What worked last quarter stops working this quarter, and most teams discover the problem when business outcomes start to decline.
It’s the inevitable consequence of deploying static artifacts into dynamic environments. Models trained on historical patterns assume those patterns are static. When they don’t, performance drops behind the scenes until someone notices that model recommendations no longer match reality.
Model decay is the cumulative effect of model drift, which manifests in two ways. First, it can be data drift when the nature of your input changes due to new users beginning to use your app or a sensor on the factory floor aging. Second, and more serious, is concept drift. It occurs when the relationship between your inputs and outputs alters, such as when a global economic change renders your previous definitions of normal consumer spending obsolete. Both can happen simultaneously, but catching the moment model stops producing reliable outputs is more important than labeling the drift in the first place.
We can also group drifts into several types. For example, a fraud detection model might experience abrupt drift when attackers change tactics and recurring drift tied to holiday shopping seasons. Each drift needs different monitoring strategies and retraining schedules.
Production-ready AI infrastructure treats drift as an expected operational condition. In practice, teams continuously monitor input distributions and the quality of predictions and receive automated alerts when performance degrades below acceptable thresholds, and develop retraining pipelines that remove the need to intervene every time drift appears. The solution principles of MLOps play a major role in making model updates routine.

MLOps in Action: Automating Model Retraining and Deployment
Automation in MLOps is often viewed as a way to move faster or as a goal to be reached for efficiency alone. However, we see its primary value in lowering operational risk from uncontrolled lifecycle changes and minimizing human error arising from manual management of production models.
An MLOps pipeline example designed for long-running systems addresses three risks every team faces at some point. They are delayed responses to performance degradation, inconsistent deployment practices, and the loss of institutional knowledge when team members change roles. Continuous delivery of model predictions is achieved through automated retraining triggered once new data lands and updates the deployment via safe rollouts, such as canary deployments or A/B testing.
A well-governed MLOps pipeline implements automated validation gates to verify model accuracy and security at each stage of development. Automated workflows initiate new builds upon data arrival, but restrict production access to candidates that statistically outperform the existing model. If regression occurs, the pipeline preserves the stable version and alerts the team for manual review. Reducing deployment risks, the benefits of MLOps are more notable the more models teams operate simultaneously.
Despite the push for autonomy, we remain advocates for a human-in-the-loop philosophy at critical junctions. It’s safe to automate repetitive, error-prone tasks such as data shuffling and environment provisioning, but it should always be a human expert who decides the final go/no-go on major architectural modifications.
Common Challenges Slowing MLOps Implementation
If MLOps were purely a technical hurdle, it would have been overcome with a standard engineering playbook. In truth, the most pressing issue in any MLOps project example is the organizational misalignment between teams with different priorities and ways of working.
Unclear Ownership
The symptoms of ownership ambiguity show up immediately after the model goes live. Production incidents activate a cycle of finger-pointing between the creators of the model and the architects of its environment. Accountability is best recovered by treating data and models as products with defined quality standards and success measures.
Data Quality Issues
The second most ubiquitous hurdle is missing or poor data quality. This challenge intensifies in production environments, considering models consume inputs from multiple upstream systems, each having distinct validation standards and failure modes. MLOps architecture patterns from enterprise examples reveal that data validation and versioning are as critical as model training itself. Yet many teams continue to perceive data as a given.
Tooling Sprawl
In an attempt to scale fast, teams end up with a loosely coupled collection of MLOps software. One platform for experimentation, another for training, a third for monitoring, and so on. Such arrangements lead to brittle workflows alongside integration overhead that grows with every new tool. Plus, knowledge becomes siloed as different team members master different platforms.
Skills Gaps
MLOps sits at the intersection of data science and software engineering. The problem is that most data scientists aren’t trained in production deployment patterns. And most platform engineers lack the ML expertise to effectively tune model-serving infrastructure. Organizations either invest in upskilling existing teams or accept that cross-functional collaboration will require extra coordination effort. Both approaches work, but require more discipline than most teams initially anticipate.
Making MLOps Work for Your Organization
The MLOps use cases covered here share operational realities that transcend industry boundaries. They all address the core risks of degraded models, uneven data quality, and manual processes broken down under production load. Understanding these challenges is the starting point. To build systems that last, one needs engineering discipline, infrastructure maturity, and sustained focus, resources that most teams struggle to allocate while maintaining existing ML initiatives.
If your ML ambitions are outpacing your operational capacity, let’s define what a resilient MLOps foundation looks like for your specific environment. Contact our team to find a realistic path to production systems.
FAQs
What are the most common MLOps use cases in enterprises?
Enterprise MLOps use cases vary by industry, with fraud detection and demand forecasting among the most common for financial services and retail. The manufacturing sector benefits from predictive maintenance to improve defect detection, and healthcare relies on predictive diagnostics. To build and sustain these capabilities, teams need standardized MLOps architecture patterns to manage data drift and maintain model accuracy over time.
Why do machine learning models fail without MLOps?
Machine learning models fail without MLOps because production environments change faster than models can adapt. Without MLOps practices such as model monitoring and automated retraining loops, model accuracy degrades in the face of data drift and shifting user behavior. MLOps provides the operational controls needed to detect failures early and maintain machine learning systems reliable and relevant after deployment.
Is MLOps only relevant for large companies?
MLOps is vital for organizations of all sizes since even a standalone production model requires automated validation to remain reliable. Large enterprises focus on scaling hundreds of models, and smaller teams use MLOps to prevent technical debt and ensure that limited engineering resources are not consumed by manual troubleshooting. Using a lean MLOps framework helps startups and mid-sized companies achieve the operational stability needed to grow without the risk of model failures.
How does MLOps improve collaboration between data science and engineering teams?
MLOps improves collaboration between data science and engineering teams by replacing manual hand-offs with a unified production pipeline and shared accountability. MLOps reconciles research and operations by providing a common set of tools and automated validation gates that satisfy the data scientists’ need for experimentation and the engineers’ requirement for system stability.
How do MLOps use cases differ from traditional DevOps practices?
In traditional DevOps, functional code and infrastructure equate to a stable system. MLOps, however, must account for the unpredictable evolution of data. A flawless ML deployment can still lead to inaccurate results as real-world inputs change. Therefore, MLOps extends the CI/CD paradigm to include continuous training (CT) and specialized monitoring for statistical drift so that the system adapts to changing real-world conditions.
Subscribe to blog updates
Get the best new articles in your inbox. Get the lastest content first.

Recent articles from our magazine







Contact Us
Find out how we can help extend your tech team for sustainable growth.

