
Building Conversational AI with LLMs: Architecture, Trade-Offs, and Implementation Realities
- June 22, 2026
- 9 min read
- AI/ML
Contents
Contents
Large language models lowered the barrier to building conversational AI. A team can connect an LLM to a chat interface, upload a few documents, and create a functional prototype in a matter of days. This accessibility has accelerated interest in conversational AI across customer support, employee productivity, operations, and digital experience initiatives. Modern LLM conversational AI systems can retrieve information, support workflows, interact with business systems, and assist users across a wide range of requests.
The challenge is that successful prototypes and production-ready systems are not the same thing. Many organizations begin evaluating an AI chatbot solution expecting the language model to be the primary consideration, only to discover that reliability, governance, integrations, knowledge management, scalability, and operational oversight often determine long-term success. Retrieval mechanisms, orchestration layers, security controls, monitoring, and integration patterns all influence how the system performs in real-world environments.
In this article, we explore the architectural approaches, implementation challenges, and technology decisions involved in building conversational AI for business that can deliver sustainable value beyond the demo stage.
How Conversational AI with LLMs Expands Business Capabilities
Rule-based chatbots and intent classifiers had a fixed ceiling. You defined the flows, mapped the intents, and maintained decision trees. They were predictable, but brittle — one edge case outside the predefined paths, and the user hit a dead end. Every new use case meant more manual maintenance.
Conversational AI with LLMs works differently. Instead of matching user input to predefined patterns, the model interprets meaning from context. Building on advances in natural language processing (NLP) and generative AI, these systems can support a broader range of interactions without requiring every possible scenario to be manually designed in advance.
The shift changes the types of problems conversational AI can help address while improving the overall user experience (UX). Modern systems can summarize information, retrieve knowledge from multiple sources, assist users through complex processes, and support employees or customers across a wider variety of requests. A customer support assistant, for example, can help explain policies, surface relevant documentation, and guide users through troubleshooting steps within a single conversation.
These capabilities come with a trade-off that often catches teams off guard: the same flexibility that makes LLMs useful also makes them unpredictable in ways that scripted systems aren’t. The focus of system design shifts from defining every response in advance to establishing the boundaries, retrieval mechanisms, governance controls, and business logic that guide how the model operates. In practice, this is why successful conversational AI initiatives depend on much more than the LLM itself.
Core Strategies for Building Conversational AI in Business
There’s no single conversational AI architecture that fits every use case. The right approach depends on your data environment, latency requirements, update frequency, and how much the system needs to “know” about your specific domain. In practice, most production systems combine elements of two foundational strategies.
RAG (Retrieval-Augmented Generation): Giving Your AI Access to Current Knowledge
Retrieval-Augmented Generation is currently the dominant architecture for conversational AI business automation that needs to work with organizational knowledge. The basic idea: rather than relying only on what the model learned during training, the system retrieves relevant information from your own data sources at query time and includes it in the prompt context.
This means your documents, policies, product catalogs, support histories, and knowledge base articles are converted into vector embeddings and stored in a vector database (Pinecone, Weaviate, and others). When a user submits a question, the system searches for relevant content, provides that information as context, and then uses the LLM to generate a response grounded in the retrieved data.
This approach offers several advantages:
- Easier knowledge updates. Business information can be updated in the underlying knowledge sources without retraining the model.
- More current responses. The system can access up-to-date information rather than relying solely on data available during model training.
- Greater transparency. Organizations gain better visibility into the sources used to generate responses.
- Reduced risk of hallucinations. Responses are grounded in verifiable content instead of depending exclusively on the model’s internal knowledge.
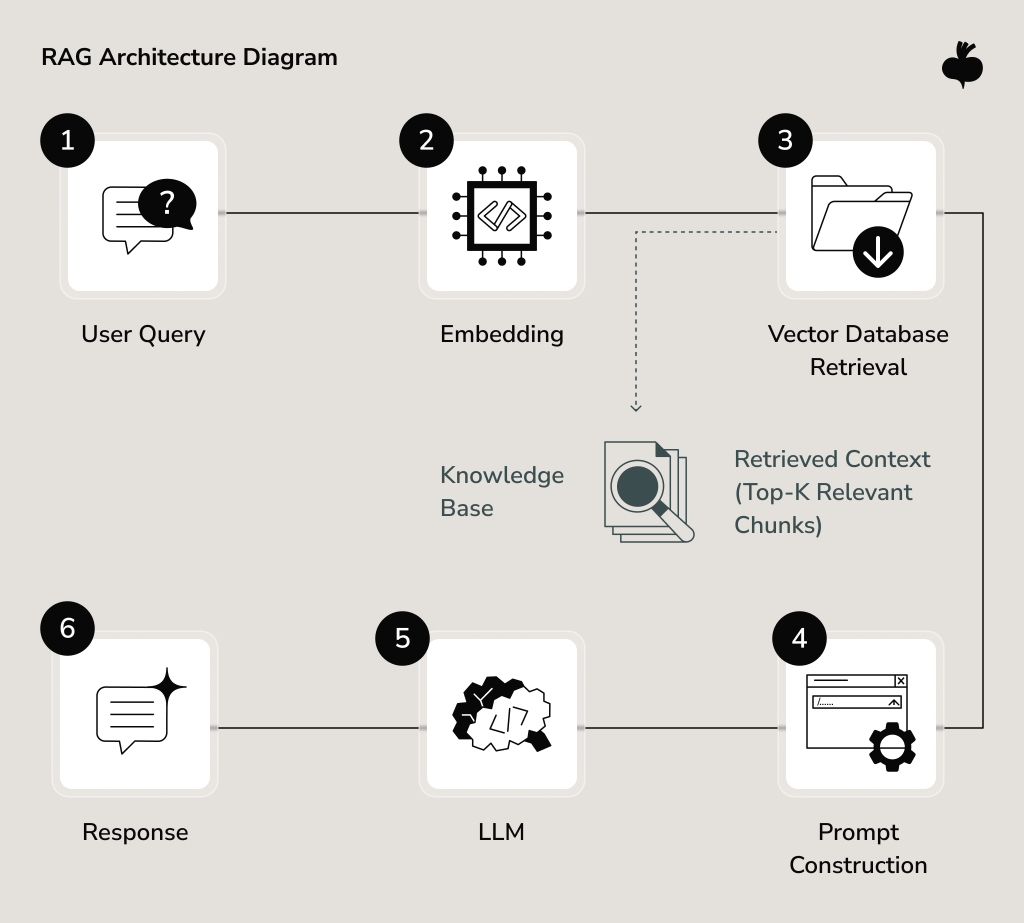
The effectiveness of RAG, however, depends heavily on the quality of the retrieval layer. Poorly organized content, weak search performance, or incomplete knowledge repositories can limit response quality regardless of how capable the underlying model is. Many modern implementations rely on vector databases to improve semantic search and retrieve context that aligns more closely with user intent rather than exact keyword matches.
For a detailed look at how different RAG configurations perform across real scenarios, our RAG vs Fine-Tuning goes deeper on architecture trade-offs.
Fine-Tuning: Training Your AI for Specialized Behavior
Fine-tuning adjusts the base model’s weights using domain-specific training examples. Where RAG provides context at inference time, fine-tuning changes how the model processes and generates language at a more fundamental level.
This approach makes sense in specific situations: when you need consistent tone and terminology that can’t be achieved through prompting alone, when you have a very large volume of representative domain examples, or when the task requires a style of reasoning that differs substantially from general-purpose model behavior. Fine-tuning can also improve latency for high-volume applications, because a smaller fine-tuned model may outperform a larger general model on specific tasks.
Fine-tuning requires curated, high-quality training data, a resource many organizations underestimate. It also creates a maintenance burden because when the domain changes, you need to re-train. And unless you’re running your own infrastructure, you’re passing training data to a third-party provider, which raises data privacy questions that procurement and legal teams will ask.
For this reason, many organizations use fine-tuning and RAG together. RAG provides access to current information, while fine-tuning helps shape behavior, improve consistency, and align outputs with specific business requirements.

Technical and Operational Challenges of Conversational AI Architecture
The growing availability of LLM as a service platforms has made it easier for organizations to build conversational AI prototypes without developing foundation models from scratch. Moving from a successful pilot to a production-ready system, however, introduces a different set of challenges. As conversational AI becomes integrated into business workflows, you must balance accuracy, performance, governance, security, and long-term operational sustainability.
Hallucinations and Response Reliability
Hallucination, the model generating plausible but incorrect information, is the risk that tends to get the most attention, and for good reason. In customer-facing or compliance-sensitive contexts, a confident wrong answer can cause real damage.
RAG substantially reduces hallucination risk in domain-specific queries, but it doesn’t eliminate it. Models can still misinterpret retrieved context, blend information incorrectly, or generate plausible-sounding details not present in any source. Effective mitigation combines architectural choices (grounding, citation tracking, confidence scoring) with operational measures, such as human-in-the-loop review for high-stakes outputs, clear user-facing disclosures, and ongoing monitoring of response quality.
Latency
Low-latency systems matter more than many teams anticipate at the design stage. A user interacting with an AI assistant in a customer service context expects response times measured in seconds, not tens of seconds.
Production latency depends on model size, infrastructure, retrieval pipeline speed, and prompt length. Token optimization is often the highest-leverage lever for improving response time. Streaming responses (returning output token by token rather than waiting for the full response) significantly improve perceived latency even when total generation time is unchanged.
Scalability and Cost Management
A conversational AI prototype serving a small user group often behaves differently from a system supporting thousands of simultaneous conversations. Increased usage can expose infrastructure bottlenecks, retrieval performance issues, and rising operational expenses.
Maintaining long-term scalability requires careful planning around infrastructure, model selection, caching strategies, and workload management. Organizations must also monitor API costs and apply token optimization techniques where appropriate, particularly when conversations involve large context windows or frequent retrieval operations.
Data Privacy and Governance
When you send user inputs and retrieved business data to a commercial LLM API, that data leaves your infrastructure. For most organizations, this triggers questions that need answers before production deployment: Does the API provider use inputs for model training? What data residency requirements apply? How are inputs logged and retained?
Major API providers (OpenAI, Anthropic, Google) offer enterprise agreements with explicit data handling terms. Understanding what those terms actually say and validating them against your compliance requirements is not optional for regulated industries. For environments where data cannot leave internal infrastructure, self-hosted or private cloud deployments of open-weight models are increasingly viable, though they come with their own infrastructure and maintenance overhead.
Integration Complexity
Connecting a conversational AI system to real business systems, such as CRM, ERP, ticketing platforms, and internal APIs is often more complex than the AI layer itself. Authentication, rate limiting, error handling, data schema mismatches, and partial failure scenarios all need careful design. Agentic workflows raise the stakes further: a model that can write records or trigger processes needs well-defined guardrails, permissions, and rollback mechanisms.

Cost Factors in Conversational AI Development
API costs are visible and predictable. You pay per token, and most providers publish their pricing. What catches teams off guard is everything else.
- Infrastructure for retrieval. Vector database hosting, embedding generation, and retrieval pipeline maintenance add consistent operational cost that grows with your knowledge base.
- Orchestration and tooling. Frameworks like LangChain or LlamaIndex simplify development but add dependency management overhead. Custom orchestration layers built for specific business logic require ongoing engineering attention.
- Prompt engineering and evaluation. Getting prompts right for your specific use case is iterative work. Evaluating output quality at scale requires tooling and processes that don’t come out of the box.
- Monitoring and operations. Production systems need observability: logging, anomaly detection, quality dashboards, and processes for handling incidents when the system behaves unexpectedly. This is an ongoing cost.
- Model updates. When your API provider releases a new model version, your system may behave differently. Regression testing before updating model versions is an operational need.
A realistic budget for a production-ready conversational AI system includes all of these, not just API usage. Teams that plan for the API cost and forget the surrounding system frequently face budget overruns when they try to operationalize.
This cuts to the heart of what makes conversational AI hard to scope. In many deployments, model usage represents only a fraction of total cost. Retrieval infrastructure, integrations, monitoring, governance, and ongoing optimization often account for a significant share of long-term ownership. The model is one line item. The system around it is the project.
How to Choose the Right Tech Stack for Your AI Assistant
There’s no universal answer here, but there are useful questions that narrow the decision.
- What is your data environment? If your knowledge lives in structured databases, RAG with hybrid search may outperform pure vector retrieval. If it’s unstructured documents, semantic search pipelines become more important.
- What are your latency requirements? Real-time customer-facing applications need different infrastructure choices than internal async workflows. Smaller models, edge deployment, or response streaming may be necessary for tight latency budgets.
- What does your compliance posture require? Regulated industries (healthcare, finance, legal) often need private deployment options, audit logging, and data residency guarantees that commercial API tiers don’t provide by default.
- What is your expected query volume? High-volume applications may benefit from smaller fine-tuned models or caching strategies for common queries. Low-volume but high-complexity applications may justify using frontier models without optimization.
- How fast will your knowledge base change? Fast-changing content (pricing, policies, product updates) favors RAG architectures where updates don’t require model retraining. Stable, specialized domains may be better candidates for fine-tuning.
On the model side, the question of the best LLM for conversational AI in business rarely has one answer. Frontier models from major labs, including OpenAI’s GPT-5 family, Anthropic’s Claude Opus models, and Google’s Gemini line, offer some of the strongest general reasoning, multimodal, coding, and agentic capabilities. Small language models (SLMs) like Microsoft’s Phi series, Google’s Gemma family, selected Meta’s Llama models, and Mistral/Mixtral variants can be highly competitive on narrower tasks, run more cost-efficiently at scale, and can be deployed privately or locally. The right choice depends on the task, risk profile, latency needs, cost model, and deployment constraints — not the benchmark rankings alone.
For orchestration, LangChain and LlamaIndex remain widely used for retrieval pipelines. For production observability, purpose-built tools like LangSmith or custom logging pipelines are worth the investment early.
Whatever stack you choose, plan for it to evolve. The tooling and model landscape is moving faster than any production roadmap can track. Building with modularity in mind, so that you can swap retrieval strategies or model providers without rebuilding the system, is practical engineering, not over-engineering.
If your team doesn’t have deep experience with these trade-offs, working with engineers who have built generative AI systems in production can significantly compress the learning curve. Organizations that recruit data scientists and AI engineers with hands-on deployment experience are often better equipped to navigate these decisions.
Final Thoughts
Building conversational AI business applications is no longer primarily a model selection exercise. While advances in language models have expanded what conversational systems can do, production success depends on how effectively those models are connected to business knowledge, workflows, governance controls, and operational processes. Decisions around retrieval, orchestration, integrations, security, monitoring, and scalability often have a greater impact on long-term outcomes than the choice of model itself.
If you’re evaluating where to start or working through specific architectural decisions, our team has worked through various problems across industries and can help you scope and sequence the work. Talk to us about what you’re building, there’s no standard engagement, and the right first step depends on where you are.
FAQs
What is the difference between traditional chatbots and LLM-powered conversational AI?
Traditional chatbots follow predefined rules, decision trees, or scripted responses. LLM-powered conversational AI uses large language models to understand context, generate natural responses, and handle a wider range of questions without relying entirely on predefined flows.
Is company data safe when using commercial LLM APIs?
Company data can be protected when commercial LLM APIs are configured with appropriate security controls, access restrictions, and data-handling policies. Data privacy depends on the AI provider, deployment model, regulatory requirements, and how the conversational AI system is designed and managed.
Should businesses choose off-the-shelf AI tools or custom conversational AI systems?
The choice between off-the-shelf AI tools and custom conversational AI systems depends on business requirements. Off-the-shelf AI tools can accelerate deployment, while custom conversational AI systems provide greater control over integrations, workflows, governance, and user experience.
How can AI hallucinations be reduced in conversational systems?
AI hallucinations can be reduced by grounding conversational AI systems in trusted data sources, using retrieval-augmented generation (RAG), implementing validation mechanisms, and continuously monitoring response quality. No conversational AI system can eliminate hallucinations entirely, but these practices can reduce their frequency.
How long does it take to deploy a production-ready conversational AI solution?
A production-ready conversational AI solution typically takes several weeks to several months to deploy, depending on system complexity, integration requirements, governance controls, security reviews, and testing requirements. Simple deployments can be completed faster than enterprise-scale implementations.
Subscribe to blog updates
Get the best new articles in your inbox. Get the lastest content first.
Recent articles from our magazine




Contact Us
Find out how we can help extend your tech team for sustainable growth.