
Contents
Contents
A pattern most teams running production AI will recognize. A marketing team launches an AI agent for content generation or analytics Q&A. A month later, the bill is $18,000 instead of the expected $800. Nobody understands why. That’s where token sprawl starts to show up.
Many marketing teams still approach AI as a fixed expense — another SaaS subscription with a predictable monthly fee. In practice, it isn’t. AI costs are variable and granular, tied to the structure, frequency, and orchestration of API calls across the system.
This is a recurring problem we cover, among others, in our AI development cost breakdown: the cost model behind the AI operation tends to fail before the model itself does.
In this article, we’ll walk through the main sources of token sprawl in production marketing systems, the remediations that map to each, and a practical order of working through them.
What Is Token Sprawl and Why Marketing Operations Run Into It First
Token sprawl describes what happens when LLM usage scales faster than anyone can track the per-token cost. The term is borrowed from infrastructure, where it describes resources that grow without unit-cost discipline. Applied to LLMs, the unit is the token.
Token sprawl compounds because each inefficiency makes the others more expensive. A bloated system prompt costs a fixed number of tokens per call. If retrieval pulls more context than needed, the same bloated prompt runs against a larger context window. If questions require multi-step reasoning, the inflated input is sent through several model calls per answer.
What is a token?
A token is a small chunk of text the model processes:
- Roughly four characters per token.
- Pricing is per token, on both input and output.
- Every API call gets billed end-to-end.
Marketing teams run into token sprawl for operational reasons more than technical ones because:
- AI adoption inside marketing tends to move faster than the governance around it.
- Content, analytics, and automation workflows get built by different teams, often on the same API, without shared cost visibility.
- Nobody owns the token budget the way engineering owns infrastructure spend.
And unlike cloud compute, which most companies now track with FinOps discipline, LLM API costs sit in a grey zone between software tooling and infrastructure, which means they often go unmonitored until the invoice lands.
Sprawl is one of the most common hidden costs of AI in marketing operations because nothing breaks. The system works perfectly, and the bill is the only signal. By the time the AI marketing budget comes up in a quarterly review, the question stops being “what does it cost” and becomes “what is it costing us right now, this hour.”
The Core Economics Behind LLM Tokens
LLM pricing has three major cost factors. Caching, batching, and tool-call policies add further complexity at scale, but these three drive most of the variation teams encounter in practice.
First, input versus output tokens. Both are billed, but output is usually more expensive, often around 5 to 6× the input rate across current model generations.
Second, model tier. Providers offer light, mid, and flagship options, and the gap between them is wider than most teams realize.
As of May 2026, standard LLM prices per million tokens are listed below:
- Light tier. Claude Haiku 4.5 costs $1 per million input tokens and $5 per million output tokens. GPT-5.4 Nano is cheaper, at $0.20 per input and $1.25 per output.
- Mid-tier. GPT-5.4 Mini costs $0.75 for input and $4.50 for output, while GPT-5.4 costs $2.50 for input and $15 for output. Claude Sonnet 4.6 is priced at $3 and $15, respectively.
- Flagship tier. Claude Opus 4.7 costs $5 per million input tokens and $25 per million output tokens, while GPT-5.5 costs $5 for input and $30 for output.
The flagship-vs-workhorse decision (Opus 4.7 vs Sonnet 4.6 vs Haiku 4.5, GPT-5.4 vs GPT-5.5, or even GPT-4 vs GPT-3.5 Mini, and whichever models come next) is a cost question with a quality dimension. Routing thousands of product descriptions through Opus 4.7 instead of Haiku 4.5 is the difference between a $50 task and a $250 task. In most contexts, the human reader cannot tell the outputs apart.
Third, the context window. The context window determines what the model processes on each request. Every token included in the request contributes to the cost, whether or not it meaningfully helps the answer. Prompts, RAG chunks, chat history, and reasoning all count — the model bills for tokens processed, not for the parts that turn out to be useful.
Where the cost actually lands is rarely where teams expect it. Not the user’s question, which might be 30 tokens. The system prompt that appears before it, which might be 1,500. The 18 RAG chunks were pulled from the retrieval layer because no one set a relevance threshold. The chain of thought the model generated to answer something that needed two sentences.
That is where the bill accumulates and the ROI of AI conversation breaks. The costs are immediate. The benefits are diffuse and slow. By the time someone tries to reconcile them, the bills are six months ahead of the attribution model.
Six Sources of Token Sprawl in Production Marketing Systems
Token sprawl rarely comes from one place. It compounds across multiple layers of a pipeline. The same six triggers keep surfacing in the audits we run.
1. System prompt bloat (too much context)
You send huge system prompts on every request. 2,000 words of brand guidelines, formatting rules, and examples — for a user who asked “What was the CPA for campaign X yesterday by hour?” The same logic repeated in every request is pure waste.

2. Loading data without purpose
The LLM is not your data warehouse. Stop sending the model full tables, raw logs, or large files. Send pre-processed, filtered, relevant slices instead. The model has no concept of indexing, deduplication, or which columns matter — that’s the warehouse’s job. Pre-aggregate in the warehouse, then pass only the columns the model needs. This is a one-off data engineering investment that pays back in under a sprint.

3. Poor RAG routing
If your RAG (Retrieval-Augmented Generation) pipeline is weak, it returns 20 chunks where 3 to 5 would have answered the question. A lot of irrelevant context gets passed to the model. As your data grows, retrieval quality drops and token counts explode. We’ve watched this curve in production:

Same question. 4.4x the cost. Nobody changed a line of prompt code.
4. Question complexity creep
At the start of a project, the questions are simple Q&A. Six months in, they’ve matured from “what happened to CPA yesterday?” to multi-step reasoning, anomaly detection across dimensions, and breakdown by channel, creative, and audience.
More reasoning means more tokens — in the prompt, in the retrieved context, and in the chain of thought the model produces to answer. The chain of thought grows. The prompt grows. Monitoring stays where it was.
The catch is structural: the worse your data is shaped, the more hops the model takes to answer. Keeping the data model close to the questions being asked is what keeps the chain of thought short.
5. No control over the model (no guardrails)
No max_tokens, no prompt size limit, no retrieval cap, no per-request cost telemetry — and the system scales usage silently. There are no guardrails, no alerts, no per-request cost visibility. Nothing goes wrong, which is the dangerous part.

6. Model switching without cost awareness
This issue is especially common in content teams. Someone migrates from a $1-per-million-token model to a $15-per-million one because the output looks a bit nicer. The task hasn’t changed, but each call consumes more tokens — heavier models tend to produce longer outputs — and each token costs more. Costs spike 15x or more overnight. Nobody notices until the invoice arrives.
All six sources at a glance
| # | Source | What happens | Anti-pattern | Better approach |
| 1 | System prompt bloat | Massive instructions on every call | 2,000-word prompt for simple queries | Minimum viable prompt per intent |
| 2 | Unfiltered data | Full tables/logs passed to model | Dump raw DB tables into context | Pre-aggregate in data warehouse first |
| 3 | Poor RAG routing | Too many irrelevant chunks retrieved | Top 20 results regardless of score | Limit to top 3 to 5 with score threshold |
| 4 | Complexity creep | Simple Q&A becomes multi-step reasoning | No prompt versioning or monitoring | Track tokens per query type over time |
| 5 | No guardrails | System scales usage silently | No max_tokens or size limits | Set hard limits and cost alerts |
| 6 | Model switching | Switched to a heavier model, costs spike | Flagship model for all tasks | Match model tier to task complexity |

A Simple Mental Model for AI ROI
Here is the formula:
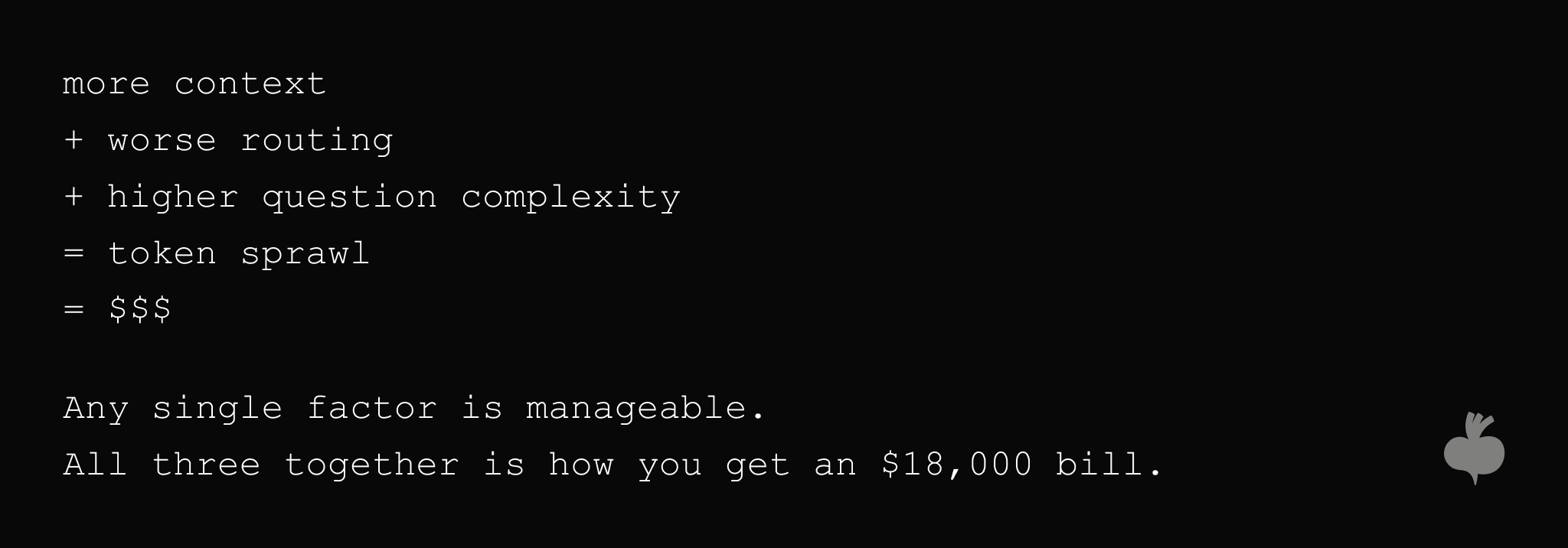
Question complexity is the hardest one to catch. A team can absorb a slightly bloated prompt or slightly loose retrieval. Combine both with a model tier nobody audited, while complexity is creeping, and the ROI of AI flips from positive to negative within a quarter.
The math on AI breaks not because models are too expensive. It breaks because the key assumption is that the operating model is free. Marketing teams who’ve been running predictive analytics solutions for a decade already know this pattern. AI didn’t introduce the cost-attribution problem — it just made it shorter and louder.
What Actually Helps the AI Marketing Budget: Six Remediations Mapped to the Six Sources
Each fix below maps directly to one or more of the six sources above. The order in the next section is not arbitrary. It reflects what returns the most cost savings per hour of effort, starting with the least expensive work and building toward the changes that touch production code.
1. Cut prompts to the minimum (source 1)
Audit system prompts every quarter. Remove old caveats, duplicate examples, and dead rules. Prompt engineering is template pruning, not hoarding.
Trade-off: You lose output stability on edge cases. Handle those in code, not the prompt.
2. Preprocess in a data warehouse (source 2)
Pre-aggregate, filter, and transform data before the API call. Run it through BigQuery or Snowflake. Then, pass the model only what it needs to best respond to the user request.
Trade-off: Every new AI workflow requires its own warehouse pipeline, which slows iteration when use cases multiply.
3. Top 3-5 RAG with a relevance threshold (source 3)
Cap retrieval at the top 3-5 results, and require a minimum relevance score so low-scoring matches get dropped rather than padded in to fill the cap. Better routing trumps a larger context window.
Trade-off: Long-tail queries occasionally need broader context. Build an escalation path for those rather than padding every call.
4. Cache responses and embeddings (sources 1, 4, 6)
Identical queries should never be sent to the model twice. Cache responses on hot paths and cache embeddings to skip recomputation.
Trade-off: Cache invalidation logic needs ownership. Stale cached answers can mislead users when underlying data shifts faster than the TTL.
5. Make tokens-per-request a KPI (source 5)
Per-request token monitoring should be on the same dashboard as CTR, CPA, and conversions. Set hard ceilings on max_tokens, prompt length, and retrieval count. Wire alerts to the channel where the team actually reads them.
Trade-off: Monitoring infrastructure has its own cost, and someone has to own the alerts when they fire.
6. Match model tier to task complexity (source 6)
The routing decision matters more than the model choice. Use light models for classification, summarization, and reformatting. Use flagship models for genuine reasoning. Document the rule per workflow so it survives team changes.
Trade-off: The tiering matrix needs maintenance as LLM API pricing shifts every few months.

A Practical Roadmap to AI Operational Efficiency
The six remediations are best sequenced by how much cost-per-hour of effort each one returns. The goal is a budget-friendly AI marketing operation that holds up as adoption grows: predictable spend, defensible numbers at the quarterly review, and no surprise invoices in between. The least glamorous work goes first, because it costs the least to do and uncovers the most. Our usual ordering looks like this.
- Week 1: Audit prompts. Instrument per-request token monitoring and set hard limits on max_tokens and retrieval size. This is the least expensive, quickest, and most boring work in the list. And it’s also the one you should do first.
- Months 1-3: Clean up RAG routing. Implement response and embedding caching on high-traffic routes. These fixes touch code, and they take engineering time. But this is where the largest cost savings come out. Eliminating redundant AI workflows often falls out of this work as a side effect.
- Ongoing: Treat token cost as a marketing KPI. Use the same dashboard as CTR, CPA, and conversions. The teams that hold this discipline keep their AI marketing budget stable as adoption grows.
| Phase | Actions | Effort | Typical impact |
| Week 1 | Audit system prompts. Instrument per-request token monitoring. Set hard limits on max_tokens, prompt size, and retrieval count. | Low | Surfaces the worst offenders. Caps the bleeding. |
| Months 1 to 3 | Clean up RAG routing with score thresholds. Implement model tiering by task complexity. Add response and embedding caching on hot paths. | Medium to high | 40% to 60% lower cost per output. Redundant workflows drop out as a side effect. |
| Ongoing | Treat token cost as a marketing KPI alongside CTR, CPA, and conversion. Same dashboard, same review cadence. | Low, but continuous | Keeps the AI marketing budget stable as adoption grows. |
Token Sprawl Is a Discipline Problem, Not a Model Problem
Most marketing teams are still in the first phase of AI adoption, where the question is: can we make this work? The teams that have moved past that phase are already asking the next question: what does it cost us per unit, and who owns that number?
Nothing in the six remediations we discussed today is technically hard. Prompt audits, retrieval thresholds, caching, and model tiering are well-understood engineering practices applied to a new kind of bill.
What’s hard is treating AI spend like the variable cost it is — measured, governed, and attributed — when the rest of the marketing stack still books it as a SaaS line item.
Every quarterly review, the AI bill comes up for defense — explaining why it grew, justifying what stays, negotiating what gets cut. The teams that have made the variable-cost shift don’t have that conversation. They have a budget.
This is the kind of work that goes into Beetroot’s custom generative AI engagements. If you’re running production AI systems and the numbers don’t line up, that’s a conversation worth having.
FAQs
Why can inefficient prompts significantly increase AI spending?
Inefficient prompts increase AI spending because every additional word is billed as an input token on each API call. A long prompt reused thousands of times per month can become a major cost driver, even when large parts of the prompt add little value to the final answer.
What is model tiering, and how does it help optimize costs?
Model tiering is the practice of assigning each AI task to the smallest and least expensive model that can produce the required level of quality. It helps reduce costs because flagship LLMs are significantly more expensive than lightweight models, while many marketing tasks such as summarization, classification, and reformatting do not require advanced reasoning capabilities.
What tools can help monitor token consumption?
Token consumption is usually monitored through three layers: API-level request logging, observability platforms like Datadog or Grafana, and internal dashboards that connect AI usage with business metrics. Effective monitoring should track not only token volume, but also cost per workflow and cost relative to business outcomes.
How can you identify an inefficient AI workflow?
An inefficient AI workflow usually shows three warning signs: token usage grows over time without improving output quality, the same model tier is used for tasks with very different complexity levels, and there are no cost limits or usage alerts in place. Prompt audits and token monitoring often reveal these inefficiencies early.
What are the first steps to optimizing AI operations in marketing?
The first steps to optimizing AI operations in marketing are auditing system prompts for unnecessary complexity, enabling per-request token monitoring, and setting limits on output size and retrieval volume. These relatively inexpensive changes often identify the biggest opportunities to reduce API costs and improve workflow efficiency.
How much should we budget for AI marketing tools?
AI marketing budgets vary depending on API call volume, model selection, workflow complexity, and the scale of automation across the organization. Small teams using AI for limited content generation may spend only a few hundred dollars per month, while mid-sized companies running AI across content, analytics, personalization, and customer workflows can spend several thousand to tens of thousands of dollars per month on API usage alone. The actual budget depends primarily on usage volume and the model tiers powering those workflows.
Subscribe to blog updates
Get the best new articles in your inbox. Get the lastest content first.
Recent articles from our magazine





Contact Us
Find out how we can help extend your tech team for sustainable growth.