
Delivery Bottlenecks in Cloud Projects: Is the Problem Your Tech or Your Team?
- April 24, 2026
- 10 min read
- Cloud
Contents
Contents
Cloud delivery slowdowns rarely have a single cause. Infrastructure problems and team dysfunction tend to co-occur, and fixing one without addressing the other rarely resolves the underlying issue.
Yet most engineering leaders see these as separate problems: adding new tools when the real problem is how the team works together, or changing team structure when the real issue is a fragile system for testing and delivering code. Beetroot’s cloud engineering teams run into this problem often, and it happens in many industries.
Knowing how to tell the difference between a bottleneck in cloud computing systems and a problem within the team is the first step to fixing them.
The High Cost of Cloud Delivery Delays: Bottleneck in Cloud Computing
Cloud delivery delays cause more problems than just missing release dates. New features pile up, opportunities to outpace competitors are lost, and costs rise as unused systems continue running. According to Flexera’s 2026 State of Cloud Report, around 29% of cloud budgets were considered wasted, often due to growing cost complexity induced by AI and new IaaS/PaaS offerings.
Massive investment in AI models and infrastructure is the primary driver for increased cloud usage. This spending now accounts for almost one quarter of all IT budgets, and Gartner forecasts global IT spending will surpass $6 trillion in 2026.
These trends highlight a broader pattern: cloud transformation risks increase when unresolved delivery issues persist, turning delays into long-term inefficiencies. To understand where these risks originate, it’s worth looking at the specific bottlenecks that tend to slow cloud delivery down.
When technical debt = delivery tax
Technical debt accelerates this dynamic considerably. When that debt is concentrated in legacy infrastructure, it slows subsequent delivery cycles and makes cloud scalability significantly harder to achieve.
The bottleneck problem in cloud environments is not only a technical one. Delivery delays degrade cloud computing performance metrics across the board: deployment frequency drops, change lead time extends, and change failure rates climb. Recognizing this as a compound problem, part infrastructure and part organizational, is the foundation for addressing it effectively. Addressing it effectively starts with visibility into the full software delivery lifecycle (SDLC), where both infrastructure and team-level friction tend to surface first.
Common Technical Bottlenecks in Cloud Projects: DevOps Bottlenecks and Legacy Systems
Problems in the CI/CD pipeline are some of the most common issues that slow down the system. When it takes a long time to build or when deployment steps have to happen one after another, the continuous delivery process flow slows down for every change. Teams try to make up for this by grouping releases together, which makes it riskier to deploy and harder to fix problems quickly. As outlined in Cloud Architecture Patterns That Support Continuous Delivery, well-defined infrastructure as code (IaC) practices are foundational to predictable deployments.
The modernization debt you keep deferring
Deferred legacy modernization compounds these problems. When modernizing legacy systems is postponed, older components act as constraints on the entire delivery pipeline. A CIO Dive survey found that nearly three-quarters of technology executives reported technical debt was actively hampering enterprise modernization, with more than a third attributing the problem to rushed cloud migrations.
Scalability misalignment and automation gaps
Cloud scalability misalignment creates additional friction. Systems designed for a constant workload struggle when the number of users rises or falls. If you cannot easily plan for more users, you end up dealing with problems as they occur rather than preparing ahead of time.
Automation bottlenecks make the case even worse. Even with automated tests, if every step still requires manual approval, you miss out on the true speed and efficiency that continuous delivery can deliver.

How Team Dynamics Can Thwart Cloud Projects
Organizational issues cause problems with delivering work that look like technical issues, such as slow releases and unexpected results, but cannot be fixed by adding more tools.
When nobody owns anything
Unclear ownership is the most consistent predictor of organizational drag. When teams are not sure who is in charge of keeping the platform running smoothly, making sure releases are ready, and checking for security, decisions get delayed and problems build up over time. Research on cloud operating models shows that organizations using a site reliability engineering (SRE) approach with clear responsibilities can launch products 20% faster and make fewer mistakes when making changes.
Silos that turn handoffs into bottlenecks
Communication silos amplify this effect. In organizations where development, operations, and product teams operate independently, context gets lost between handoffs. In organizations where development, operations, and product teams operate independently, communication gaps cause context to get lost between handoffs.
Scaling DevOps teams without addressing these boundaries often adds coordination overhead rather than delivery capacity. McKinsey consistently finds that culture is the primary obstacle to transformation success, with organizations that invest in cultural change alongside technical upgrades achieving success rates 5.3 times higher.
Poorly structured DevOps processes tend to emerge when teams adopt the tooling without the organizational changes that make it effective. Continuous delivery becomes a label rather than a practice, and pipelines are used inconsistently across teams.

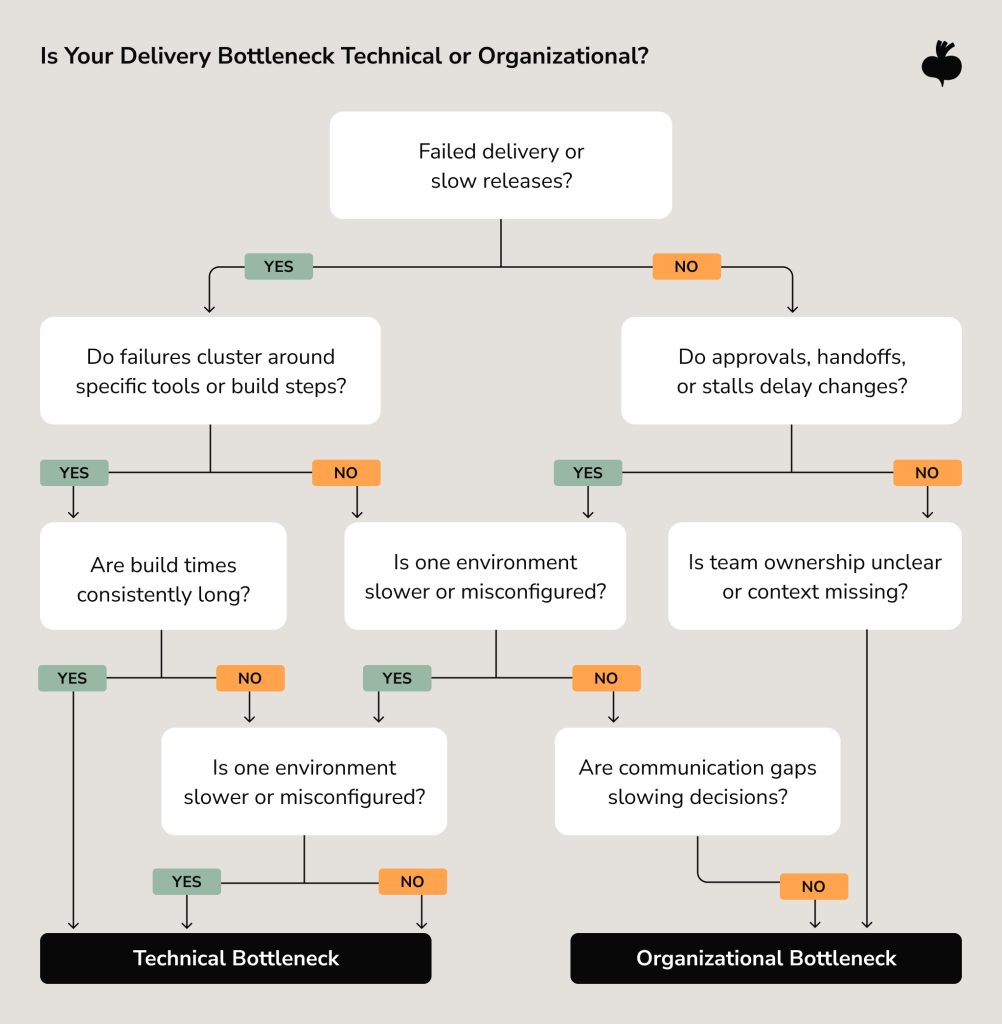
Tech vs. Team: Identifying the Root Cause of Project Slowdowns
Distinguishing between infrastructure bottlenecks and organizational misalignment requires a structured diagnostic approach. The same problem, a failed deployment, can happen because the process is fragile, the setup is wrong, or the work is not passed on clearly. Fixing the wrong cause wastes time and does not solve the real bottleneck problem.
Map the delivery flow before you diagnose anything
A practical starting point is mapping the software delivery process flow end-to-end. Follow a normal change from when it is first made to when it goes live, paying attention to where time adds up, where waiting for approval slows things down, and where problems keep happening. This shows whether delays mostly occur because of specific technical parts, when work is passed between people, or when decisions are made.
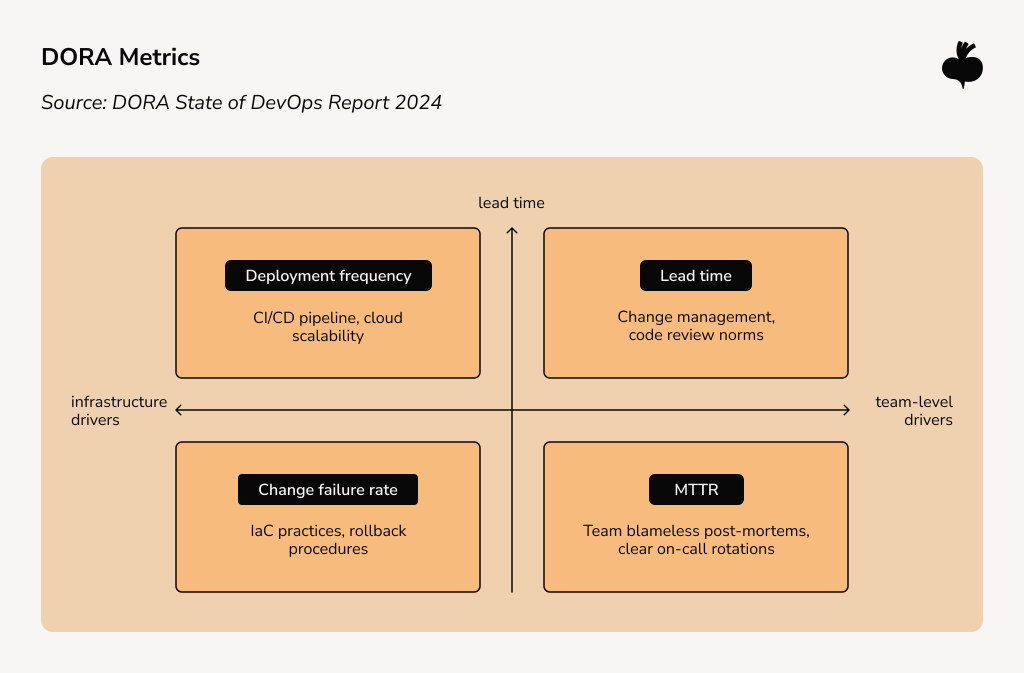
What DORA metrics actually tell you
Cloud computing performance metrics provide a parallel diagnostic layer. The DORA 2024 State of DevOps Report, using feedback from over 39,000 professionals, shows that doing poorly in all four DORA areas (how often you release updates, how quickly you make changes, how often changes fail, and how fast you fix problems) usually means there are both technical and team issues.
If only one or two measurements are showing problems, the cause is probably limited to a specific area. The way the system is designed usually decides what kind of slowdown the team deals with most, a distinction covered in detail in the cloud-native vs cloud-enabled vs cloud-agnostic comprehensive comparison.
Best Practices for Identifying Cloud Delivery Bottlenecks: Tools and Methodologies
Identifying a bottleneck problem requires observability at multiple levels: the infrastructure, the pipeline, and the team workflow. Without measuring, efforts to improve usually focus on what is easiest to see instead of fixing the real problems.
- At the system level, tools like OpenTelemetry, Datadog, or Prometheus help find slowdowns in different parts of the software and cloud services. Using these together with dedicated bottleneck software helps engineering teams see more clearly where delays happen most often during the delivery process.
- In the pipeline, CI/CD analytics show how long builds take, how long jobs wait in line, and where failures happen at each step. A build that is always slow is a different issue from one that only gets slow when there is a lot of activity.
- Using value stream mapping for software delivery shows where work gets stuck and where it moves forward, which helps find delays between teams that technical tools might not catch. As explored in our piece on cloud project acceleration, looking at the whole delivery process before hiring more people often shows that the problem is with how the work is done, not with the number of staff.
That is where cloud optimization solutions add the most value: identifying the actual constraint before committing resources to fixing the wrong one.
Overall, reviewing change management data alongside deployment data rounds out the picture: frequent reverts and skipped releases signal a bottleneck in project management or team process that is as significant as any infrastructure constraint.
Taking Care of Infrastructure Bottlenecks in Multi-Cloud Environments
Multi-cloud environments amplify existing infrastructure bottlenecks. Gartner forecasts that 90% of organizations will adopt hybrid or multi-cloud strategies by 2027. As more environments are added, using different tools, having unpredictable delays, and changes in settings between providers create problems that are much harder to figure out than problems in just one cloud.
- Architectural standardization is the most effective mitigation. Using the same infrastructure tools across different providers, such as Terraform or Pulumi, makes it easier to set up in a consistent way that is easy to track, check, and review. If teams do not use the same approach, each group ends up doing things differently, making it harder to share knowledge and slowing down cross-team work.
- Cloud performance optimization solutions in multi-cloud setups also require deliberate latency management. Making sure cloud services do not always have to wait for each other and planning for what happens if connections between clouds fail can make things run faster and more reliably.
The relationship between architectural lean-ness and delivery speed is examined directly in our latest article on sustainable cloud design.
Fixing a Dysfunctional DevOps Team: Strategies for Smoother Delivery
When DevOps process bottlenecks originate in team structure rather than tooling, organizational adjustments outperform any technical intervention.
#1. Start with ownership clarity
Clarifying ownership at the team level is the highest-leverage starting point. When a component has a clear owning team, issues are resolved faster, and maintenance standards improve. Ambiguity about ownership is a reliable predictor of technical debt accumulation across all organization sizes.
#2. Build internal platforms to reduce cognitive load
The next step is to start using platform engineering. Creating in-house tools that cover the complex parts of the system makes things easier for product teams, ensures DevOps is more consistent across the company, and lets experts focus where they are most helpful. Growing DevOps teams this way helps deliver results more reliably without making teamwork harder.
#3. Shared rituals that create shared context
Better cross-functional collaboration brings everything together. When teams share on-call duties, review incidents together, and set common OKRs, they build the shared understanding needed for strong results. The analysis of one organization that adopted the SRE operating model found a 60% reduction in change failure rate and a 30% reduction in labor spend.
None of the abovementioned changes require new tooling. They require leaders to agree on direction and to provide steady support for how work is organized. Teams that make these changes often see clear improvements in delivery velocity within the first few release cycles.

How Automation Helps Fix Problems in Cloud Delivery
Problems with automation often show up when not everything is covered. A process that automates testing but still needs someone to approve every staging release does not give the speed benefits of continuous delivery. It just moves the slowdown to the approval step. Good automation needs to cover the whole process, not just parts of it.
Equally important is recognizing what automation cannot fix. An automated deployment process running on poorly designed infrastructure still fails at scale. Automation operating within a team structure that has unclear ownership still produces inconsistent results.
Teams that set up tools to monitor their processes and check how much work is automated often find that what looks like faster progress is offset by more manual work elsewhere. Using bottleneck software to monitor these patterns continuously helps teams prevent problems before they occur, rather than just fixing them after they occur.
Building a Balance Between Tools and Talent for Efficient Cloud Projects
To achieve sustained cloud delivery speed, engineering leaders need to align two factors that are often managed separately: the technical architecture’s maturity and the team’s ability to run it.
Over-investing in tooling without developing the team’s ability to use it effectively produces the same outcome as underinvestment: poor delivery performance, with a higher tooling budget. Building strong team practices around an architecture with fundamental scalability constraints will eventually hit a ceiling that process changes alone cannot raise.
Measure delivery health continuously, and not just after another incident
Improvement roadmaps need to address both dimensions in parallel. When a team diagnoses a bottleneck in project management or delivery flow, the question should be: is this primarily a tooling gap, a process gap, or both?
According to the DORA 2024 State of DevOps Report, high-performing teams have one thing in common: they keep a close eye on their performance, letting real data guide their choices instead of relying on faded memories of past challenges. For teams trying to do this with not enough people or resources, getting help from outside experts can speed up progress in both areas without starting over from scratch.
Conclusion
Cloud delivery bottlenecks rarely resolve on their own, and they rarely have a single cause. The best improvement programs treat technical limits and how teams work together as related issues, figure them out together, fix the most important ones first, and track results with numbers that show the whole process from start to finish.
Teams that always deliver quickly and safely know exactly where their problems are. Getting that clear view means spending time and resources on watching how things work, honestly looking at what went wrong after issues, and being willing to fix process problems with better ways of working, not just new tools. If you are facing a specific delivery issue, our team can review your setup and help you identify simple next steps.
FAQs
What are the most common bottlenecks in cloud delivery projects?
The most common bottlenecks in cloud delivery projects fall into two categories: infrastructure and organizational. Infrastructure bottlenecks include slow CI/CD pipelines, inconsistent infrastructure-as-code practices, and cloud scalability misalignment. Organizational bottlenecks include unclear team ownership, communication silos between development and operations, and DevOps processes adopted as tooling without the underlying cultural and structural changes that make them effective.
What tools help identify bottlenecks in cloud computing performance?
Tools that help identify slow spots in cloud computing include tracking platforms such as OpenTelemetry, Datadog, and Prometheus, which show how the system is functioning, and analytics that indicate how well the software delivery process is running. Mapping out the steps in software delivery can reveal delays when work is passed between people and slowdowns caused by waiting for approvals, which technical tools alone might miss.
Can automation fully resolve DevOps process bottlenecks?
Automation cannot fully fix DevOps process bottlenecks when the real problem lies in how the organization works, not the technology. Automation is good at automating boring, repetitive tasks like setting up environments, running tests, and updating passwords. However, automation applied to a poorly designed architecture or a team with unclear ownership does not remove the root constraint. It shifts where the bottleneck appears.
How do multi-cloud environments create infrastructure bottlenecks?
Multi-cloud environments create infrastructure bottlenecks and this can lead to using incompatible tools, inconsistent settings across providers, and delays when moving between cloud services. Without a standard way to set up resources and a clear view of everything, teams develop their own ways of doing things, which makes it harder to share knowledge and slows down work.
How can organizations help DevOps teams and leaders work together better?
To spark stronger collaboration between DevOps teams and leadership, organizations can align on common delivery metrics, conduct joint post-incident reviews, and share delivery performance insights with leaders. When engineering leaders track DORA metrics alongside product and business outcomes, conversations about DevOps investment become grounded in evidence rather than perception.
Subscribe to blog updates
Get the best new articles in your inbox. Get the lastest content first.
Recent articles from our magazine




Contact Us
Find out how we can help extend your tech team for sustainable growth.
