
Contents
Contents
The data exists. The dashboards exist. Yet marketing teams managing fragmented data sources still cannot ask a plain question of the entire stack and get a single answer back. Demand-generation leaders sit on top of CRMs, web analytics, paid media platforms, content management systems, attribution tools, customer data platforms, and a long tail of internal documents.
In NIQ’s 2026 CMO Outlook, 54% of marketing leaders said they struggle to connect data from different sources. The pattern shows up consistently across recent industry research: the tools are in place, the dashboards are running, and the answers people need still take days to assemble.
Generic AI assistants do little to fix this. They generate fluent text and helpful summaries, yet they have no view of the company’s pipeline, campaign history, customer segments, or business definitions. To move from generic outputs to dependable answers, marketing leaders need an AI knowledge base for marketing teams that retrieves real internal context before generating anything. That is what RAG systems for marketing are built to do.
What a Marketing Knowledge Assistant Actually Does
An AI-driven marketing knowledge assistant answers operational questions using company data instead of the model’s general training corpus. The behavior resembles a senior analyst with a perfect memory of every internal system, rather than a chatbot offering boilerplate advice.
Typical questions look like these:
- “Why did trial signup conversion drop last week?”
- “Which channels drove the highest-quality leads this month?”
- “What changed in paid search performance after the landing page update?”
- “Show me the campaigns that touched our top 20 closed-won accounts.”
Each answer blends several sources: CRM records, attribution data, GA4 events, paid-media spend, the content calendar, and internal definitions of “qualified lead” or “campaign.” A standard LLM cannot produce these because the relevant facts are not in the model’s training data. A retrieval-grounded assistant produces them because the retrieval step pulls the matching records, and the generation step composes a readable answer from that context.
This is the operational difference that matters. A generic chatbot guesses. A grounded assistant cites.
Why RAG AI Architecture Fits Marketing Knowledge Work
The case for retrieval-augmented generation marketing benefits rests on three failure modes of standalone LLMs.
The first failure mode is hallucination. Generic models invent confident answers when they lack data. Retrieval-grounded systems narrow that gap by forcing the model to answer from documents that actually exist in the company’s systems.
The second is freshness. Marketing data changes daily; the model’s pretraining weights are frozen.
The third is cost. Stuffing whole brand books, campaign briefs, and quarterly performance dumps into every prompt drives token bills up and answer quality down.
RAG addresses all three at the architecture level. A retriever queries an indexed view of company data, returns the small subset of records relevant to the question, and feeds only that into the LLM. The LLM generates an answer grounded in retrieved facts and, in well-built systems, returns citations to the source rows.
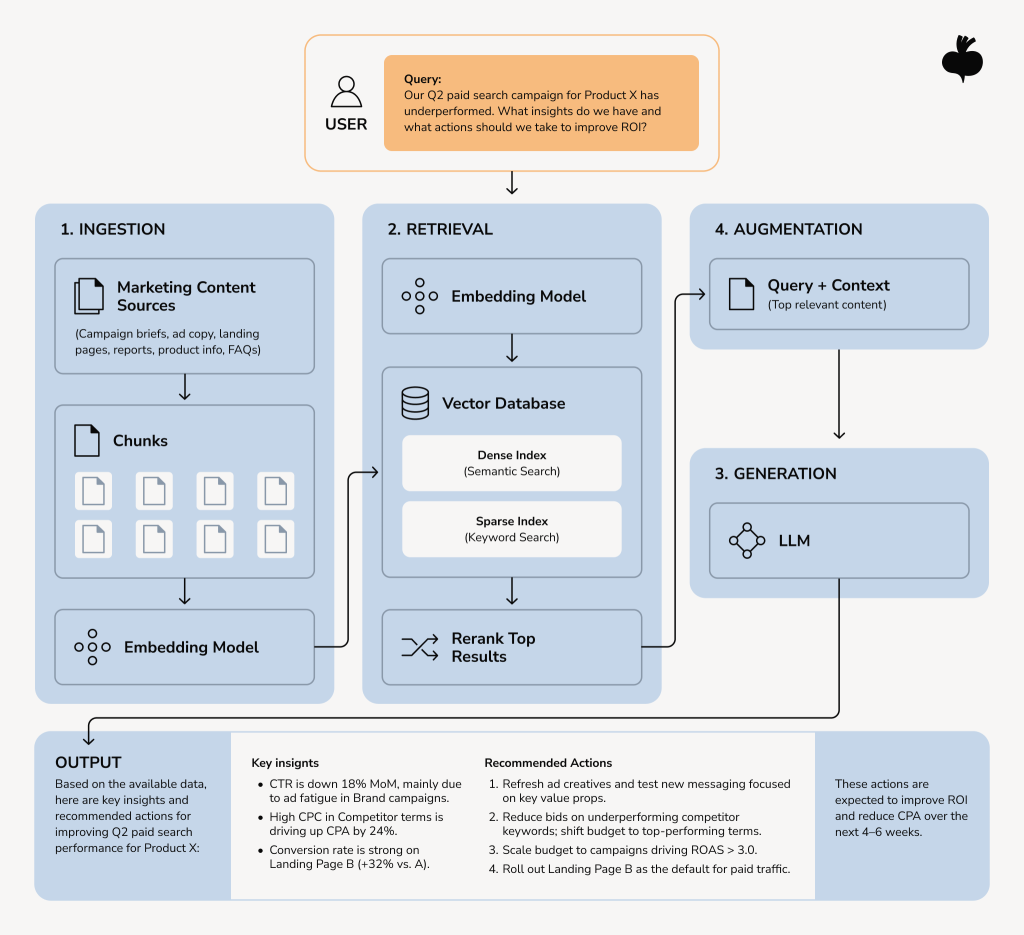
The current default RAG AI architecture for marketing knowledge work has four moving parts:
- Ingestion and structuring. Source systems are read and normalized into a form that the assistant can search. Structured records from CRM and analytics warehouses are joined with semantic context (campaign names, segment definitions, KPI glossaries). Unstructured data (brand guidelines, briefs, post-mortems) is parsed and chunked.
- Embedding and indexing. Text chunks are converted to vectors via an embedding model and stored in a vector database. Pinecone, Weaviate, and pgvector are common production choices; selection depends on latency targets, hybrid-search needs, and existing cloud commitments.
- Retrieval. At query time, the user’s question is embedded and used to find semantically similar chunks. Modern pipelines combine vector-based semantic search with BM25 keyword retrieval (hybrid search), since the two methods together consistently outperform either alone.
- Generation and citation. A reasoning-capable LLM receives the retrieved context, the original question, and a prompt that instructs it to answer only from the retrieved material and to cite sources. Frameworks like LangChain and LlamaIndex orchestrate the steps, and careful prompt engineering keeps the model constrained to the retrieved context.
The output reflects the company’s data rather than the open internet. The economic case follows from a consistent pattern: grounded answers reduce review cycles, decisions get made in-session, and analyst time shifts from routine lookups to work that compounds. The ROI shows up first in high-frequency workflows.
For a side-by-side comparison of when RAG works better than fine-tuning, see the trade-offs we have covered separately.
The Data Layer Matters More Than the Chat Interface
The most common failure pattern in marketing AI projects has little to do with the model. It is the data layer underneath.
A 2025 IBM Institute for Business Value study found that 77% of respondents agree that data silos hinder real-time analytics, and 83% say silos undermine innovation. Marketing organizations sit at the center of that fragmentation: CRM, GA4, paid media platforms, CMS, marketing automation, attribution, customer support tickets, and product analytics events all describe the same customer journey in different vocabularies.
When a RAG system is layered onto this without preparation, the retriever returns rows that are technically related to the query but semantically inconsistent. “Conversion” means one thing in GA4 and another in HubSpot. The model writes a smooth answer that combines incompatible definitions, and the marketing team loses trust within a quarter.
The fix is a RAG system design that treats the data layer as the primary deliverable. Three principles tend to apply:
- Model the business. Build a semantic layer on top of raw warehouses where entities live in marketing terms: campaigns, channels, funnel stages, accounts, customer journeys, MQLs, SQLs. The assistant retrieves from this layer rather than from raw tables. Exposing raw warehouse tables directly to an LLM creates two predictable problems: the model sees field names without business meaning, and the volume of irrelevant context drives up both cost and hallucination risk.
- Decide on the scope. The types of data sources for RAG systems that work for marketing usually start with the CRM, the analytics warehouse (BigQuery, Snowflake, or similar), paid-media exports, the CMS, the campaign brief library, and a glossary of internal definitions. Customer support and product analytics data come in later, once governance is established.
- Engineer data for LLM consumption. Chunk briefs by section; attach metadata (campaign ID, time window, owner) to every chunk. Maintain embedding versioning to keep retrieval quality stable as models change.
Production teams that get this right treat the chat interface as the thinnest layer in the stack. Designing data for LLMs as the end-user changes how the assistant handles queries and what it returns. The work that determines success sits in the pipelines underneath, which is where reliable data engineering services earn their keep. For a fuller treatment, see our AI in Marketing Operations whitepaper.

What Keeps a Marketing Assistant Safe in Production
Once the assistant works, the next question is whether it can be trusted with real workflows. Marketing data is sensitive on two axes: it includes PII (lead names, emails, account contacts) and competitive information (pipeline, attribution, paid-media performance). A production assistant that ignores either creates legal and operational risk.
Governance for a marketing RAG system tends to cover six controls:
- Role-based access controls. The assistant respects the same permissions as the underlying systems. A demand-gen specialist sees campaign data; a regional manager sees only their region; a contractor sees a sandbox.
- Least-privilege retrieval. The retriever filters chunks by the requester’s identity before they reach the LLM. Trusting the model to redact downstream is a common and costly mistake.
- Review thresholds for high-risk outputs. Answers that recommend budget shifts, customer-facing copy, or anything tied to revenue forecasts pass through a human review queue. The assistant proposes; people approve.
- Audit trails. Every query, retrieved chunk set, generated answer, and user action is logged. Auditors and security teams require this, as do engineers debugging quality regressions.
- Cost controls. Per-user and per-workflow token budgets prevent a single runaway prompt from generating a five-figure bill. Caching common queries is standard.
- Observability. Quality metrics (retrieval precision, answer groundedness, citation coverage) are monitored alongside cost and latency. Drift detection catches the moment a new data source starts polluting answers.
This frame is what makes RAG in business viable: a system that legal, security, and finance teams will sign off on for production use. Skipping governance is also one of the most common reasons why promising conversational AI projects fail, never leaving “pilot purgatory.”
Case Study: AI Marketing Copilot
One recent engagement makes this concrete. A mid-sized SaaS company with a full-funnel marketing team kept hitting a familiar wall: marketers relied on analysts for routine performance questions, resulting in a 2–5-day turnaround for insights needed within the campaign cycle.
The team designed a conversational AI copilot for marketing anchored in the company’s existing CRM, analytics, attribution, and campaign data, giving marketers instant, data‑backed answers without waiting on analysts. By structuring the data layer specifically for a large‑language model rather than traditional BI tools, the copilot can understand more questions and deliver richer insights. Security is wired in: CRM permissions flow through every query, ensuring only authorized information is displayed, and each numeric answer is accompanied by a citation to its source.
Outcomes after rollout:
- 60% fewer ad-hoc analyst requests. Most “what happened with X” questions are resolved inside the assistant.
- Turnaround compressed from days to about an hour. The marketing team started getting instant answers instead of waiting for reports, which sped up decision-making.
- Analysts moved upstream. Freed from repetitive lookups, the analytics team shifted toward reusable models, data quality, and forecasting.
- Faster campaign optimization. Decisions on creative, bidding, and budget reallocation moved closer to the data window in which they mattered.
The full story is covered in our AI for marketing analytics case study. The same architecture supports RAG for sales use cases (account research, deal coaching) on the same data foundation.

Practical Starting Point: How to Scope the First RAG Pilot
Most marketing AI projects break in the scoping phase rather than the build. The defaults that lead to durable outcomes are well known.
- Pick one high-volume, repetitive workflow. Weekly performance recaps, campaign post-mortems, or pipeline source-of-truth questions are good candidates. Avoid judgment-heavy or customer-facing tasks in the first pilot.
- Define a process owner. Assign a single person on the marketing operations side to own the workflow, the metrics, and the feedback loop. Engineering builds the system; the process owner decides whether it actually helps.
- Establish baselines before rollout. Capture time-to-answer, analyst hours per week on routine requests, and error rate in current reporting. Without these numbers, the pilot cannot prove anything.
- Run a 6-8-week pilot. Long enough to ship, short enough to force focus. Most production-quality patterns that hold up at scale are visible inside this window.
- Measure five things. Adoption (weekly active users among target marketers), answer quality (groundedness, citation coverage, thumbs-up rate), analyst-request reduction, turnaround time, and cost per query. These five elements capture both the value the system is supposed to create and the risks it should avoid.
These defaults extend across most RAG for business deployments, well beyond marketing. The reason RAG system design best practices keep returning to the same checklist is that failure modes recur in the same places: scope creep, missing baselines, unclear ownership, and over-investment in the chat UI relative to the data foundation.
For organizations treating this as a strategic investment, Beetroot’s agentic AI development services cover the full design-through-production arc, including the data engineering work that determines whether the system holds up at scale.

From Experiment to Production
The conversation in marketing has moved past whether AI assistants are useful. The honest question is whether a given organization’s data, processes, and governance can sustain it in production.
RAG systems for marketing exist to bridge that gap. Done well, they convert fragmented systems into a single conversational surface, replace days of analyst back-and-forth with grounded answers, and free analytical talent to work on the questions worth their time. Done poorly, they hallucinate, expose data, or quietly fail to gain adoption.
The difference between the two outcomes is rarely about the model. It comes down to whether the data layer, retrieval design, governance, and workflow fit are taken seriously from day one.
Our team at Beetroot designs and implements RAG-based systems integrated into real marketing workflows for organizations that want operational outcomes. To walk through a specific use case, get in touch.
FAQ
How does a marketing knowledge assistant differ from a standard AI chatbot?
A marketing knowledge assistant retrieves answers from a company’s own data, including CRM records, analytics, campaign history, and internal definitions, before generating a response. A standard AI chatbot relies on a language model’s general training data and has no view of internal systems. The marketing knowledge assistant, therefore, produces answers grounded in the organization’s actual pipeline, customers, and campaigns, while a standard chatbot produces general advice.
Which vector database is best for marketing RAG systems?
The most common production choices for marketing RAG systems are the vector databases Pinecone, Weaviate, and pgvector. Pinecone is a managed service that simplifies operations at scale. Weaviate offers strong hybrid search and supports on-premise deployment. pgvector extends an existing Postgres database and reduces architectural sprawl. The right choice depends on latency targets, search complexity, existing cloud commitments, and team preference for managed services over self-hosted infrastructure. However, marketing teams usually work with Google BigQuery which also might be used for the same purpose.
How can teams ensure data privacy when using RAG with sensitive marketing data?
Teams ensure data privacy in marketing RAG systems by enforcing role-based access controls at the retrieval layer, filtering retrieved chunks by user identity before they reach the language model, logging every query and answer for audit, encrypting data at rest and in transit, and limiting which sources are indexed in the first place. Hosting the model in a private environment or using an enterprise API with a no-training agreement adds another layer of protection for sensitive data.
How do RAG systems reduce AI hallucinations in marketing reports?
RAG systems reduce AI hallucinations by retrieving relevant company data before generation and instructing the language model to answer only from that retrieved context. Grounding answers in real internal documents removes most of the conditions under which generic models invent facts. Requiring citations on every numeric claim and routing high-risk answers through human review further reduces residual error.
Can RAG systems integrate with CRM platforms?
Yes, RAG systems can integrate with CRM platforms such as Salesforce, HubSpot, and Microsoft Dynamics 365 through APIs or via the underlying data warehouse based on BigQuery, Snowflake, etc. The integration typically pulls structured CRM records into a normalized semantic layer, where they are indexed alongside other business and marketing data sources. Access controls and field-level permissions from the CRM can also be synchronized with the retrieval layer so the assistant respects existing user access rules.
Subscribe to blog updates
Get the best new articles in your inbox. Get the lastest content first.
Recent articles from our magazine




Contact Us
Find out how we can help extend your tech team for sustainable growth.