
Contents
Contents
For many organizations, data management problems start not because of a lack of data. Most enterprises actually suffer from too much of it — collected across multiple systems, tools, and teams without coordination. Data is often poorly structured, ownership is unspecified, and trust in generated insights is low.
At some point, dashboards stop helping. Reports take weeks. Teams argue about numbers. Decisions get made on intuition — despite terabytes of data sitting in the warehouse. And AI adoption doesn’t fix this. It inherits and amplifies the noise.
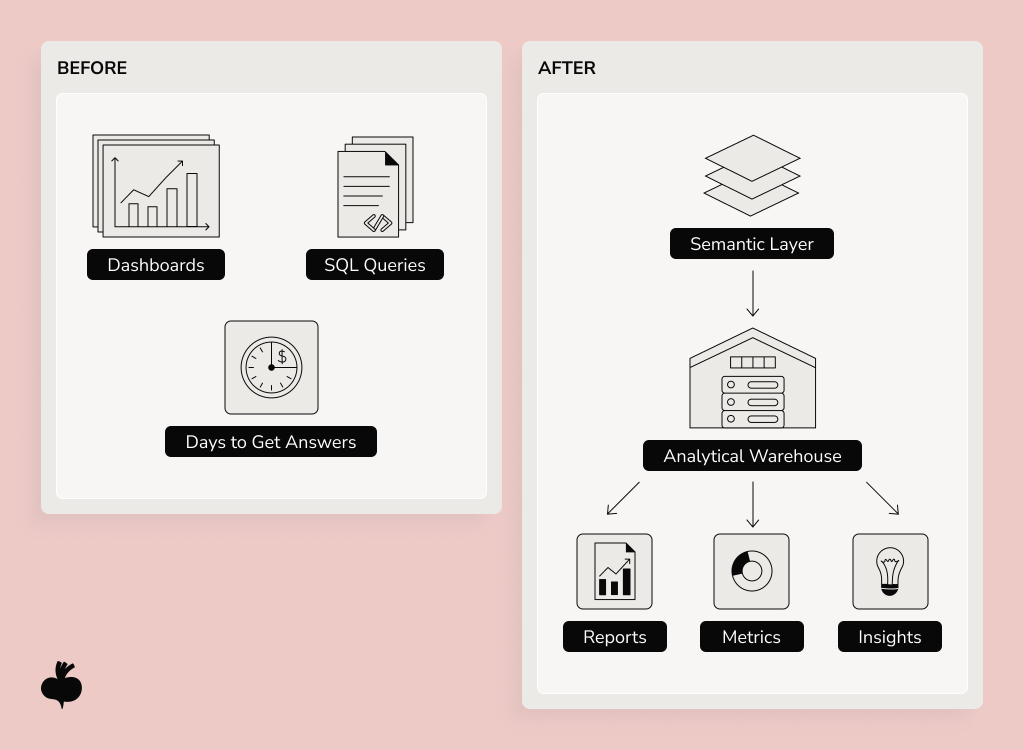
Simple questions are taking weeks to answer
A classic symptom of data management issues at scale is slow responses to questions that should be simple. If teams cannot quickly retrieve information for “What’s the revenue for last quarter?” or “Which sales channels are underperforming?”, enterprise data management doesn’t work as expected.
The main cause behind such challenges in managing data is usually architectural. The company has enough data, but it’s not modeled for analytics. Because the business logic is scattered across dashboards and ad hoc SQL queries, every new question becomes a separate project.
Instead of launching another dashboard, an enterprise must establish a centralized analytical warehouse with a semantic layer that defines metrics once and reuses them everywhere, creating a single source of truth for any query, across any team.
Tools like dbt, Looker, and Cube allow engineering teams to define metrics, dimensions, and relationships in one place. Once this foundation is ready, knowing how to solve data management problems becomes straightforward, speed comes back naturally, and answers become consistent.
Different teams get different numbers for the same metric
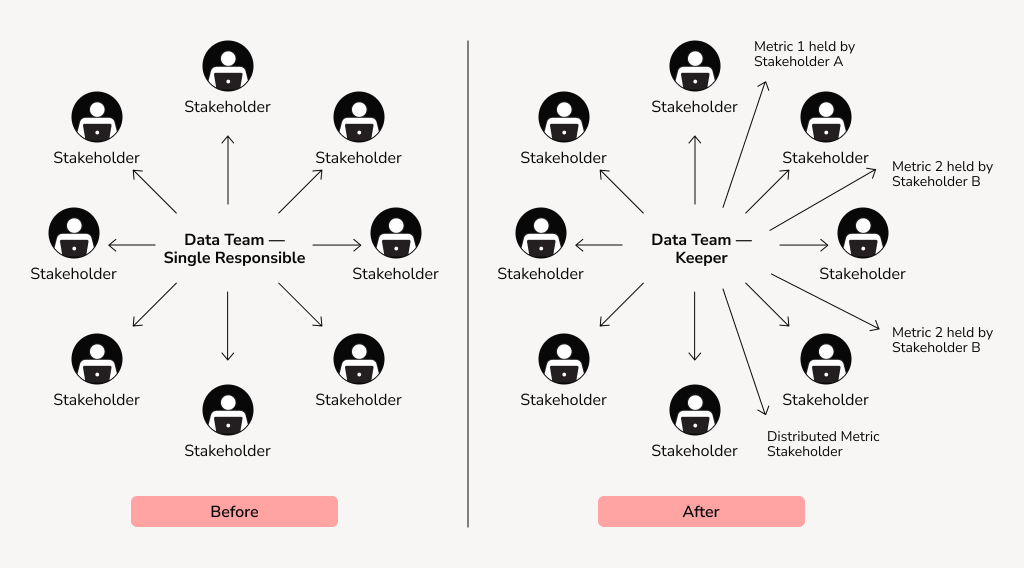
At scale, disagreements over numbers become political. Marketing shows one revenue figure. Finance shows another. Both teams believe their version is correct.
This happens when business logic is scattered across BI tools, and metrics have no clear owners. In such a case, information comes from different data pipelines, with different timing rules and granularity assumptions. Their dashboards turn into competing “truths.”
The fix isn’t easy, but it’s necessary: centralize metric definition, assign clear ownership, and document assumptions. Each key metric should have one responsible team and be stored in one location. That team approves definition changes, resolves discrepancies, and has the final say on specific data.
The nature of his challenge is organizational, not technical, and the hardest part is getting teams to accept that their version of the metric is no longer the valid one. But once the metrics become contracts rather than suggestions, trust gradually returns.
When data exists but no one trusts it
At some point, many organizations reach a stage where data is technically available, but decisions are still made based on Excel or gut feeling.
A typical issue behind such cases is not only data quality problems. It’s the lack of transparency and data lineage. Enterprises should map the end-to-end data flow, including sources, transformations (ETL/ELT), and metadata.
Data doesn’t need to be perfect for teams to build on it. It needs to be predictable. The core approaches to improve data transparency include:
- Data quality checks. Combine schema checks via SQL and dbt tests, as well as uniqueness and validity checks, to ensure data completeness and consistency.
- Freshness monitoring. Implement warehouse-native or orchestrator-based checks to regularly update data and alert teams to abnormalities.
- Clear incident ownership. Assign the owner, alert channel, incident workflow, and runbooks for each data set.
An effective way to handle data management issues and discrepancies is to define confidence intervals. Once stakeholders evaluate each metric and its confidence interval, it’s much easier to identify and prioritize problems that need fixing first.
Broken pipelines that always surprise everyone
In many enterprises, data pipelines fail silently. The problem is only discovered when a dashboard turns red or a CEO questions the accuracy of numbers.
The reason behind slow quality degradation is usually not the tooling. It’s an ownership problem. Pipelines without SLAs behave exactly as expected — unreliably, as there are no freshness guarantees, no regular data quality checks, and no clear accountability when something breaks. Teams need to address their data governance challenges before resolving those related to engineering.
Treating data infrastructure as a platform — with monitoring, alerts, and clear owners — shifts data from “best effort” to “operational”:
- Have explicit SLAs and SLOs, defining the requirements for every critical dataset (e.g., a dataset must have ≥ 99.5% completeness or be updated by 8:00 EST daily).
- Build in data observability by automatically tracking anomalies in volume, schema, and distribution.
- Assign an owner to every pipeline or dataset and instantly route alerts to them.
- Have an escalation path if data issues persist.
- Audit incidents to identify root causes and set guardrails to prevent similar issues.
Analysts spend more time cleaning data than analyzing it
When analysts spend 70% of their time fixing data, there is something very wrong with the system. It may look like cleaning logic repeatedly, trying to match tables that have too many inconsistencies, or reverse-engineering undocumented fields from raw systems.
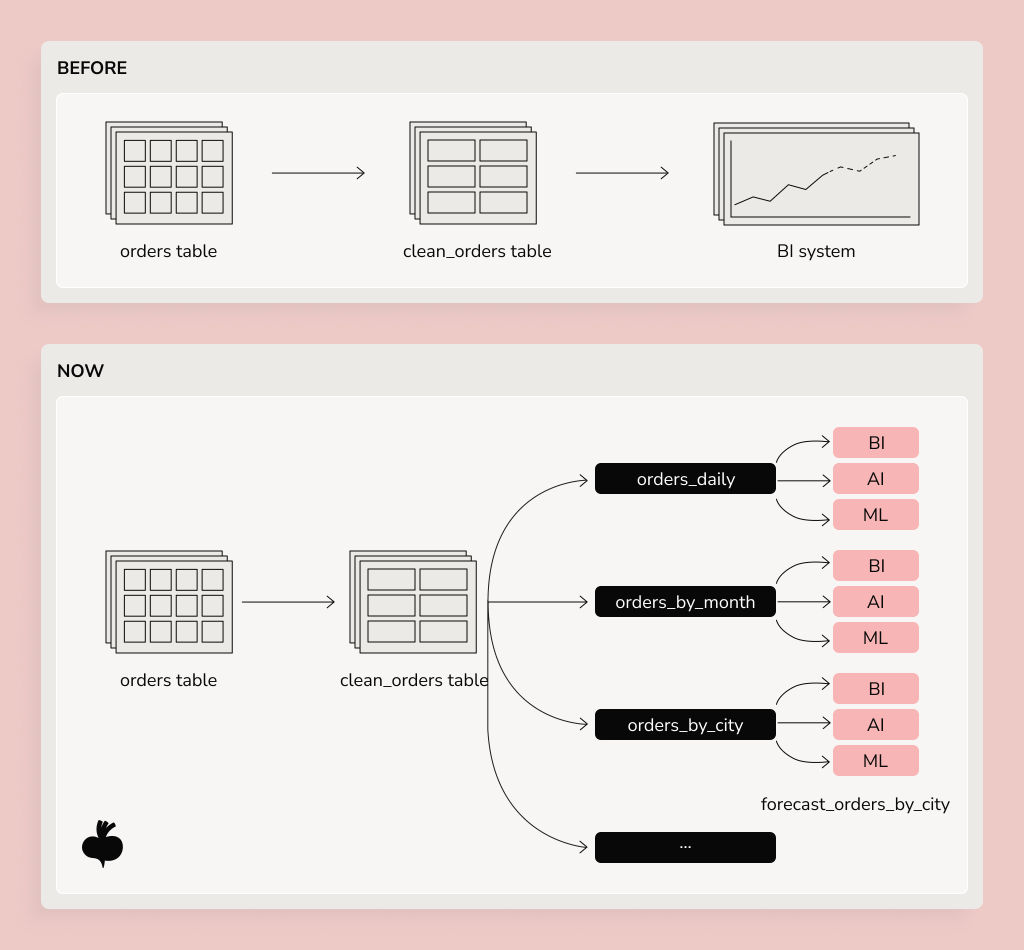
This happens when raw data goes directly into analysis without modeling, contracts, or reusable layers. SQL becomes complex, fragile, and difficult to maintain.
That’s why enterprises should build layered architectures and reusable models to automate data preprocessing. A typical data platform architecture includes a raw layer for data traceability, a staging layer for basic normalization, an intermediate layer that creates a shared business logic, and a presentation layer for specific use cases and clear metric definitions.
Layered architectures and reusable models are not a form of bureaucracy. They’re the only way to get analysts out of the plumbing and back to the insights.
Analytics explains the past but can’t predict the future
At some point, descriptive analytics stops being enough. Knowing what happened is useful, but top data teams derive more value from forecasts, early signals, and proactive decision-making.
This transition is particularly difficult for historical reasons. For most of the last decade, data teams optimized their work and data management practices for BI dashboards. Sometimes, they also reused the same data for exploratory ML research. As a result, data was rarely stored for time-series integrity, feature reuse, or long-term consistency. Teams also rarely designed it for predictive workloads or AI use cases like agents or chat-based interfaces.
Without reliable historical snapshots, feature pipelines, and reproducible transformations, forecasting remains experimental and fails to meet production-quality requirements. Even though teams can still train models, they are too fragile, hard to maintain, and difficult to trust.
A shift from an explanatory to a predictive analytics approach requires changes in how enterprises store and manage data. It means designing data models for longitudinal analysis, treating features as first-class assets, and stopping the practice of running ML jobs as one-off experiments. ML production-grade systems require continuous management to keep predictive analytics reliable.
ML implementation somehow exists, but the impact is unclear
This challenge is a continuation of the previous one. In many companies, ML “exists” in some form. They may have implemented data pipelines, models, and sometimes even production deployments. However, when a simple question comes up — what real impact these systems have on the business — there is usually no clear answer. Most often, this happens because ML was built as an ad hoc research effort or a one-time initiative, rather than a production-grade, continuous capability. An enterprise might have invested in building a model, even used it in some way, but it has never become part of decision-making, KPI tracking, or systematic experiments.
A turning point comes when ML is integrated into normal business processes and becomes a defined workflow within a team with clear rules for data preparation, testing, documentation, metric tracking, and ownership. With established processes for validating new model versions, running controlled experiments, and making regular updates, ML turns from a black box into a predictable business tool you can measure and explain.
Setting up everything might look overwhelming at the beginning, but it’s a necessary step for further ML scaling.
Data costs grow faster than the business
As data volume grows, costs tend to rise faster than expected, queries get slower, warehouses become more expensive, and the relationship between data investment and business value becomes harder to justify.
It’s typically a governance problem, not a cloud problem. Without cloud data cost visibility, query discipline, and architectural standards, scaling becomes expensive by default.
Implementing FinOps for data management brings accountability back to the stack. In practice, that means switching to incremental processing instead of full refreshes, eliminating duplicate datasets, archiving data that no longer serves an active purpose, and auditing costs regularly to catch inefficiencies before they accumulate. All of these are process and ownership decisions, belonging to the same category as most other data management problems on this list.
Data becomes a compliance risk
Enterprise data often includes personally identifiable or confidential information. As companies scale, this data shifts from being an asset to a liability. When under pressure from regulations like GDPR, ISO 27001, SOC 2, and internal audit requirements, organizations start treating data access as a risk surface.
A common response is to tighten controls. Access is limited to a small group of people, even when others legitimately need it, and getting permission turns into a long chain of approvals. Over time, self-service analytics stops working not because the data is missing, but because compliance is enforced manually and inconsistently. As a result, organizational efficiency declines.
The root cause is usually structural. Enterprises need reliable data lineage, clear separation of PII, purpose-based access, and audit logs. These are standard requirements under GDPR and ISO 27001 that, when implemented correctly, markedly reduce data risks and improve usability.
It is easier to achieve this in practice by selecting a data management platform or building on infrastructure that is compliant with the required frameworks by design, rather than trying to retrofit compliance on top of an existing stack.
Data teams slow the business down
The most dangerous stage among enterprise data management problems and solutions is not broken dashboards or slow queries, but when the business starts systematically bypassing the data team. This rarely happens because analysts or engineers are incompetent.
At some point, the data function gets pulled into processes — tickets, pipelines, and SLAs — and drifts away from the actual questions the business is trying to answer. As a result, responses come too late, lack context, or data arrives in a form that is hard to use, pushing the business to adapt by choosing speed over correctness.
The right solution here is shifting toward product thinking. Data teams need to own outcomes, not just infrastructure, and this is a stage when scalable AI solutions start to create real value. When data is available and ready for further use, applying LLMs for analysis and reasoning expands data teams’ capabilities.
AI does not replace analysts — it shortens the path from question to decision, helping them focus on business-critical matters instead of drowning in a narrow technical function.
Overcoming the Challenges of Data Management: From Problems to Structure
The listed data management problems are subtle at first. Enterprise data engineering teams notice that sometimes systems don’t work as expected, costs accumulate, and data provides little real value to the business.
Data problems rarely stem from technical issues alone and often share a similar pattern, pointing to structural and sometimes operational or managerial bottlenecks within the company. Enterprises may need to work on data quality, transparent processes, and clear ownership to make the use of data-driven systems more efficient and see the true value of technology.
When ownership, architecture, and incentives are aligned, data stops being a burden and becomes a powerful strategic leverage. Successfully addressing the foundational data problems we discussed today brings companies one step closer to the next stage, when they can automate their workflows by implementing AI agents, fine-tuning self-hosted LLMs, and developing corporate chatbots.
If any of these challenges sound familiar and you’re not sure where to start, our team at Beetroot is happy to help you work through them.
FAQs
What are the most common data management problems in enterprises?
The most common data management problems in enterprises are increasing data discrepancies across teams, a lack of data ownership, rapidly increasing costs, and compliance risks. These issues reduce the reliability of data-driven systems and prevent companies from further scaling.
Why do enterprise data projects fail despite high investment?
Enterprise data projects fail due to the lack of clear business objectives, weak data governance, and low data quality. Many initiatives focus on implementing technology without estimating its real business value. As a result, even high investments don’t pay off, and the maintenance of data systems quickly turns into a burden.
How can companies improve data quality and trust across teams?
Companies improve data quality and trust by implementing strong data governance, clear ownership, and consistent processes. The key best practices to build explainable and reliable data systems include using a centralized data warehouse with a semantic layer, establishing data standards and validation rules, assigning data management responsibilities, and continuous data quality monitoring.
What causes inconsistencies in business metrics across departments?
Inconsistent business metrics are caused by multiple overlapping data sources, conflicting definitions, data silos, and the lack of centralized governance. A typical example is when several departments calculate the cost per lead differently, which generates several versions of the same metric.
How can organizations scale data systems without increasing costs disproportionately?
Organizations can scale data systems cost-effectively by adopting FinOps best practices to optimize data processing and storage. The key FinOps optimization strategies include switching to incremental data processing rather than full refreshes, eliminating duplicate data, deleting and archiving unnecessary data, and regularly reviewing and auditing data costs.
Subscribe to blog updates
Get the best new articles in your inbox. Get the lastest content first.
Recent articles from our magazine




Contact Us
Find out how we can help extend your tech team for sustainable growth.