
An Introduction to Azure Databricks for Data Engineering & Team Collaboration
Contents
Contents
Let’s talk about the value of data first…
More than 80% of all data collected by organizations are stored in unstructured documents, log files, images, social media posts, client databases, financial records, and other digital assets. Imagine the treasure trove of insights hidden in those volumes of information! For that reason, companies increasingly leverage data using machine learning, data science, and analytics to drive strategic initiatives from unconventional business intelligence.
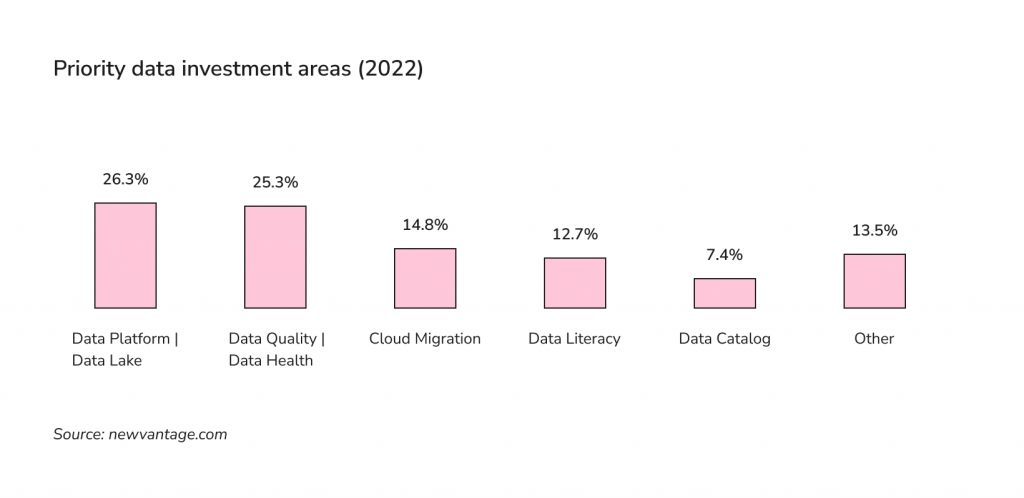
As per Wavestone’s 2022 Data and AI Leadership survey, 92.1% of respondents report receiving returns on their data and AI technology investments, 56.5% drive innovation with data, and 39.7% manage it as a business asset. Priority investment areas are now data platforms and data lake solutions (26.3%), data quality and data health (25.3%), Cloud migration (14.8%), data literacy (12.7%), and data catalogs (7.4%).
One of the most accessible and fastest collaborative tools presented in the data platform category is Azure Databricks. The top customers using Azure Databricks are companies engaged in Computer Software (19%) and Information Technology and Services (16%) segments, according to Enlyft’s recent research.
What exactly is Azure Databricks?
It is a jointly developed data and AI service from Databricks and Microsoft for data engineering, data science, analytics, and machine learning. Azure Databricks is optimized for the Microsoft Azure cloud platform and provides one-click integrations with other cloud services and environments for data-intensive applications that allow collaboration between data scientists, data engineers, and business analysts on a simple, open lakehouse.
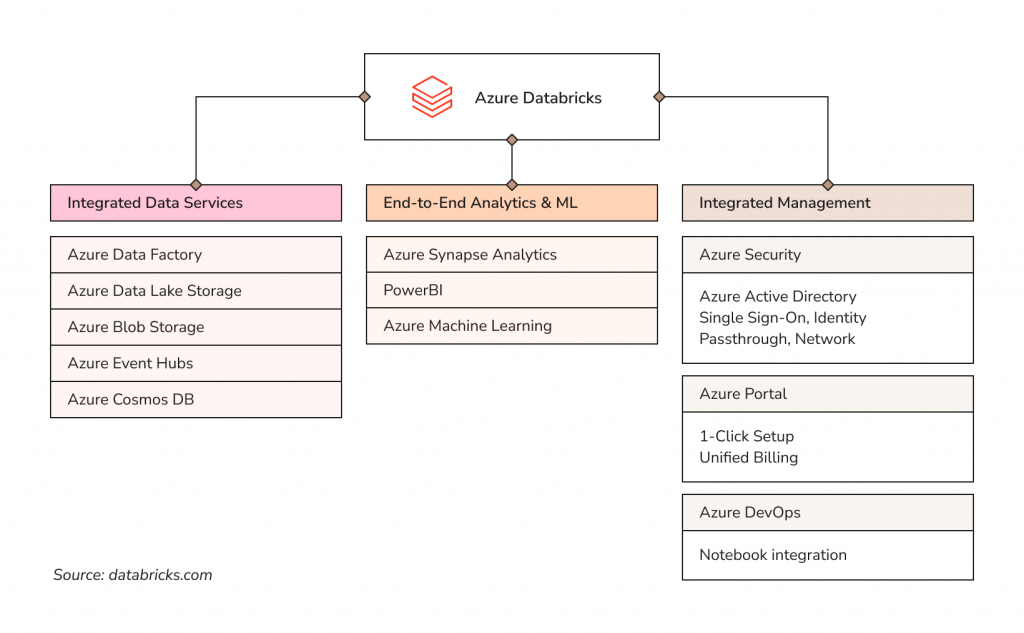
Below, we’ll focus on a general overview of some Azure Databricks resources that make it easier for data teams to generate operational value from raw data. Looking for more practical tips? Then, don’t miss our recent Youtube episode on Azure Databricks development flow presented by our guest expert and senior software engineer at Microsoft.
Azure Databricks featured components
Azure Databricks allows you to set up your production environment in minutes, run different analytic workflows on one cloud platform, and connect your data engineers by sharing projects in interactive workspaces using cluster technologies and integrated services.
Optimized Spark environment
Azure Databricks provides access to the latest version of Apache Spark with each update and supports secure integrations with open-source libraries. It has a fully-managed production environment that allows you to spin up clusters and fine-tune them to establish a certain level of performance and reliability without additional monitoring. It also includes interactive workspaces for exploration and visualization. The Apache Spark ecosystem builds on the Spark Core API, a computing engine that supports multiple languages (Scala, Python, Java, R, and SQL) for easier data engineering and machine learning development. Spark comes bundled with higher-level libraries, including support for SQL queries, streaming, machine learning, and graph processing.
Collaborative notebooks and common languages
Unifying your data, analytics, and AI workloads into one ecosystem using a common platform for all data use cases allows you to boost productivity and collaborate effectively in shared workspaces. Your teams can use notebooks in R, Scala, Python, or SQL to document all progress, create dynamic reports using interactive dashboards, and more.
Databricks Runtime
The serverless option, natively built for the Azure cloud on top of Azure Spark, enables data scientists to iterate quickly as a team by eliminating the need for specialized expertise to set up and configure your data infrastructure.
Machine Learning on Big Data
The integrated Azure Machine Learning module provides access to advanced ML capabilities and quick identification of suitable algorithms and hyperparameters. You can simplify management, monitoring, and update ML models and get a centralized registry for your experiment tracking, models, and pipelines.
Integrations
Databricks integrates with various other Azure services and stores, including Azure Data Factory, Data Lake Storage and Blob Storage, Azure Key Vault, a wide range of data sources, developer tools to work with data by writing code, and validated third-party solutions.
Azure Data Factory cloud platform solves many complex scenarios if you aim to orchestrate and operationalize processes to refine enormous amounts of raw data. You can create and schedule data-driven workflows in Azure Data Factory (pipelines) to ingest and transform data between different data sources and sinks. There are two ways to execute pipelines in Azure Data Factory: triggers or manual (on-demand execution). You can build complex ETL (extract-transform-load) processes that transform data visually with data flows or use compute services such as Azure HDInsight Hadoop, Azure Databricks, and Azure SQL Database. Also, you can publish your transformed data to data stores (e.g., Azure Synapse Analytics) and systematize raw data into meaningful data stores and data lake architecture to facilitate business decisions.
Repos for Git integration
The most significant benefit of having source control support is that you can improve your code without the risk of breaking the main version used in the job. At the same time, each developer can work in their own notebook and merge changes after development is done. For teams working on large-scale projects, Microsoft consulting services can offer expert support and help ensure that best practices are followed in the development process.
Databricks supports notebook version control integration with GitHub, Bitbucket Cloud, or Azure DevOps services, and your team can access the said repos directly from the workspace. The use of Databricks Repos simplifies the team collaboration: you can develop code in an Azure Databricks notebook and sync it with a remote Git repository, as well as use the Git functionality for cloning repos, managing branches, pushing and pulling changes, and visually comparing differences upon commit.
CI/CD workflow integration in Azure Databricks
Continuous integration (CI) and continuous delivery (CD) are part of DevOps services and operating principles that development teams use to deliver software in short, frequent cycles through automation pipelines while maintaining code quality and reliability. The repository-level integration with Git providers supports best practices for data science and engineering code development that includes the following steps but may vary depending on your needs:
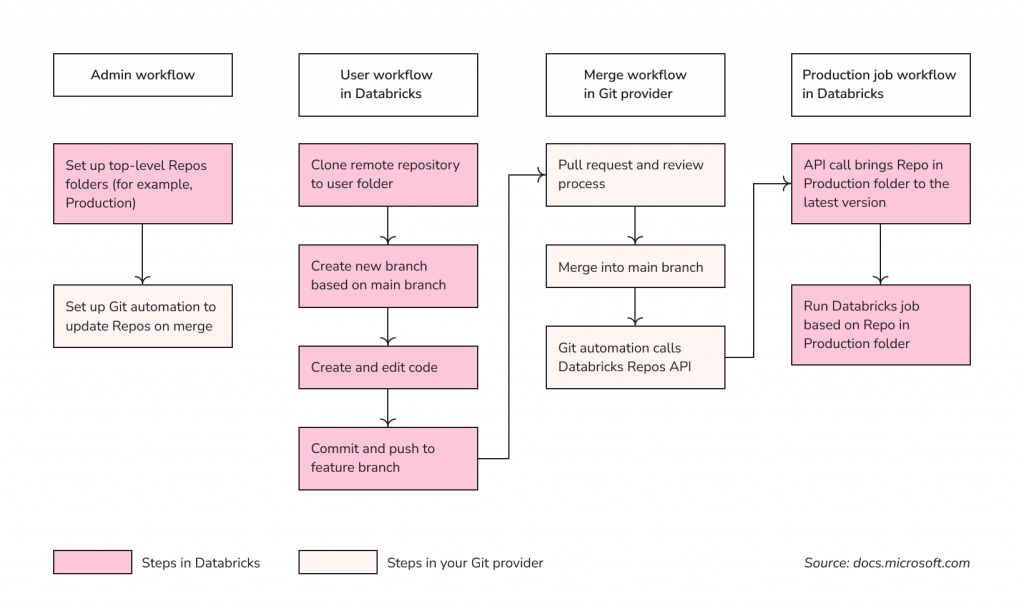
Important takeaways from this stage:
- Databricks Repos have user-level folders automatically created when a user first clones a remote repository and top-level folders (for example, Dev, Staging, and Production) containing appropriate app versions or branches. Top-level folders are created manually by Admins.
- You can set up Git automation to update repos on merge. Automation will call the Repos API endpoint on the appropriate repo to bring that repo to the latest version upon every successful merge of branches.
- The best practice for the developer flow is to create a new feature branch (or select a previously created one) for work instead of committing and pushing changes directly to the main branch. Then, merge your code when you are ready.
- Incoming changes clear the notebook state, which means that Git operations that alter the notebook source code result in losing call results, comments, revision history, and widgets. However, creating a new branch or Git commit and push do not affect the notebook source code.
- CI/CD requires continuous testing to deliver quality code and apps. The Nutter testing framework makes it easier to test the Databricks notebooks, integrates seamlessly with Azure DevOps Build/Release pipelines, and enables a simple inner development loop.
- It is not recommended to grant all team members access to the Staging folder. Folders of this type should be updated from Azure DevOps (or other Git providers) only or by running your pipelines.
Summary
Finding the best way to leverage data-backed insights in your business projects isn’t easy, but it’s worth considering if you want to grow quicker. Azure Databricks is one of the many platforms you can use to foster higher collaboration and productivity of your data engineers.
Or, you can consult with an experienced team on building a working solution to ensure data quality in your organization. Beetroot is the right place to drop anchor: we provide both dedicated teams and peak demand services tailored to your specific requirements. So, let’s connect and see how we can help.
Subscribe to blog updates
Get the best new articles in your inbox. Get the lastest content first.

Recent articles from our magazine







Contact Us
Find out how we can help extend your tech team for sustainable growth.

