
Contents
Contents
The rise of AI assistants has changed how we engage with technology, significantly boosting productivity and reducing the barriers to learning. What once required manually searching the web, reading through information, and applying knowledge can now be streamlined through conversational AI interfaces.
As technology advances, AI systems like ChatGPT, Claude, and others have gone far beyond just answering factual queries. They can understand and respond in natural language and engage in almost human-like dialogue, offering insights and creative ideas across diverse domains. Instead of sifting through search results, one can now ask a question and receive a coherent answer derived from the assistant’s extensive training data. From writing and text analysis to math and coding, AI co-pilots impressively augment our capabilities, freeing up valuable time for strategic tasks.
Yet, with so many AI assistants available, selecting the best fit for your needs can be daunting. For this post, we decided to examine some of the most popular large AI models. We’ll compare them head-to-head based on major benchmarks and their overall practical effectiveness.
LLM milestones: The fast-paced journey to modern AI assistants
The progress of large language models (LLMs) shows how quickly the field has advanced, moving from academic whitepapers to widespread public use in just a few years. LLMs are artificial neural networks built on the transformer architecture, first introduced in 2017. The rapid rise of these powerful AI systems has stirred the tech community, bringing an increased focus on the ethical implications and potential societal impacts of AI. The largest LLMs are OpenAI’s GPT family (e.g., GPT-3.5, GPT-4, and GPT-4o, currently used in ChatGPT and Microsoft Copilot), the Claude series by Anthropic, Gemini by Google (used in the chatbot formerly known as Bard), Meta’s Llama models, and Mistral AI. Here’s the short timeline of LLM breakthroughs:
| Year | Model/Release | Description |
| 2018 | BERT (Bidirectional Encoder Representations from Transformers) by Google | It marked a significant advancement in natural language processing. The model’s ability to consider context from both directions in a sentence has greatly improved performance on various language tasks like question answering and sentiment analysis. |
| 2019 | GPT-2 by OpenAI | It demonstrated impressive text generation capabilities from short prompts, sparking both excitement about AI’s potential and concerns about AI misuse, ethics, and responsible development— a reason why OpenAI initially delayed the full release. |
| 2020 | GPT-3 by OpenAI | A massive scale-up in model size and capabilities. With 175B parameters, it showed remarkable versatility. GPT-3’s ability to generate human-like text, answer questions, and write code captured significant attention from the tech community and the public. |
| 2021 | LaMDA (Language Model for Dialogue Applications) by Google; RoBERTa by Meta | Google announced LaMDA, which later became the basis for Bard. Meta (then Facebook) released RoBERTa, an optimized version of BERT. |
| 2022 | ChatGPT by OpenAI; PaLM by Google; LLaMA by Meta; Claude by Anthropic | OpenAI launched ChatGPT in November, bringing conversational AI to the mainstream. Its chat-like UI and ability to engage in human-like dialogue across a wide range of topics sparked immediate public interest. Google released PaLM (540B parameters); LLaMA, a collection of foundation language models by Meta, followed. Anthropic launched Claude, an AI assistant focused on being helpful, harmless, and honest. |
| 2023 | GPT-4 by OpenAI; Various competing models | The release of GPT-4 by OpenAI and competing models from other providers (e.g., Claude 2, Gemini (ex-Bard), Gemini Ultra, LLaMA2, and Mistral AI) accelerated the trend of integrating AI bots into numerous applications and services. They showed improved reasoning capabilities, multimodal abilities (processing both text and images), and better alignment with human values. |
| 2024 | Claude 3 series by Anthropic; GPT-4o by OpenAI | Anthropic released the Claude 3 series (Haiku, Sonnet, and Opus) in March, with Opus showing state-of-the-art performance on various benchmarks. In May, OpenAI launched GPT-4o, their flagship model. It marked significant progress in LLMs: multimodality, improved response times, and more natural human-AI interaction. This year, Apple is integrating ChatGPT (GPT-4o) into iOS, iPadOS, and macOS (available for free to their users). |

AI models leaderboards: Comparing vital benchmarks
Several benchmarks have been created to evaluate the capabilities of large language models. These benchmarks collectively assess a wide range of cognitive abilities, providing a comprehensive view of an AI model’s capabilities across various domains of intelligence.
General performance evaluation
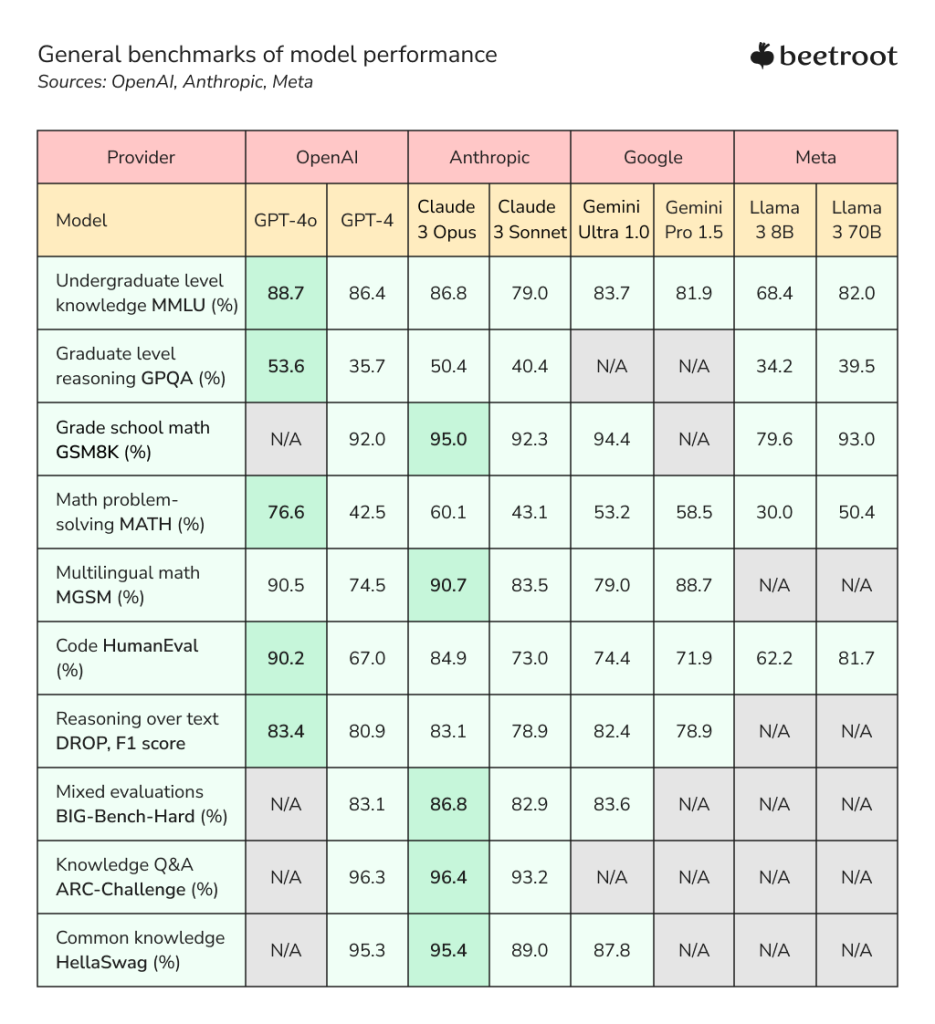
The provided data revealed impressive capabilities of LLMs in text understanding, reasoning, mathematics, coding, and general knowledge. The data reveals that AI assistants have made significant strides in handling complex tasks, often showing human-level or superhuman results. Two models stand out as the top scorers: Claude 3 Opus from Anthropic and GPT-4o from OpenAI. Claude 3 Opus shows exceptional performance in grade school math (GSM8K) with a 95% score, multilingual math, and knowledge-based tasks like ARC-Challenge (96.4%) and HellaSwag (95.4%). It also performs well in math problem-solving (MATH) with 60.1%. GPT-4o, on the other hand, outperforms in undergraduate-level knowledge (MMLU) with 88.7% and graduate-level reasoning (GPQA). It excels in coding tasks, achieving a 90.2% score on HumanEval, and demonstrates strong capabilities in multilingual math (MGSM) at 90.5% and reasoning over text (DROP) at 83.4%. Both models have slight edges in different domains, yet their overall capabilities are remarkably close, setting a new standard for AI performance.
New standards of vision understanding
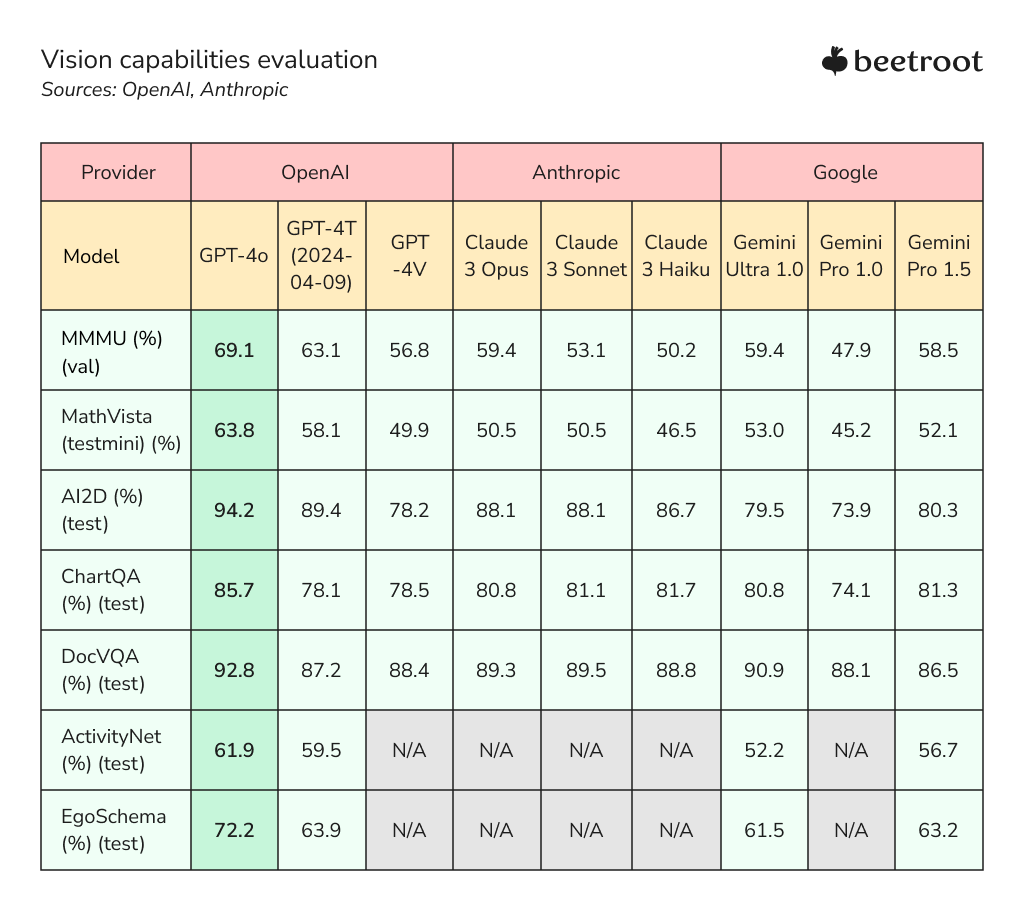
The recent benchmark results in AI visual understanding reveal significant progression across various models, with OpenAI’s GPT-4o emerging as the clear frontrunner. This model outperforms competitors across all measured tasks, from multimodal abilities and mathematical reasoning with visual inputs to chart interpretation and video comprehension. GPT-4o’s exceptional performance sets a new standard in the field, showcasing the model’s versatility and depth of understanding.
While GPT-4o leads the pack, other systems also demonstrate impressive visual AI capabilities. Anthropic’s Claude models, particularly Opus and Sonnet, show strong performance in document analysis and chart interpretation. Google’s Gemini Ultra 1.0 also presents solid results across the board, especially in document visual question answering. This level of visual comprehension opens up new possibilities for AI applications in education, scientific research, data analysis, and multimedia content understanding.
Audio translation and speech recognition
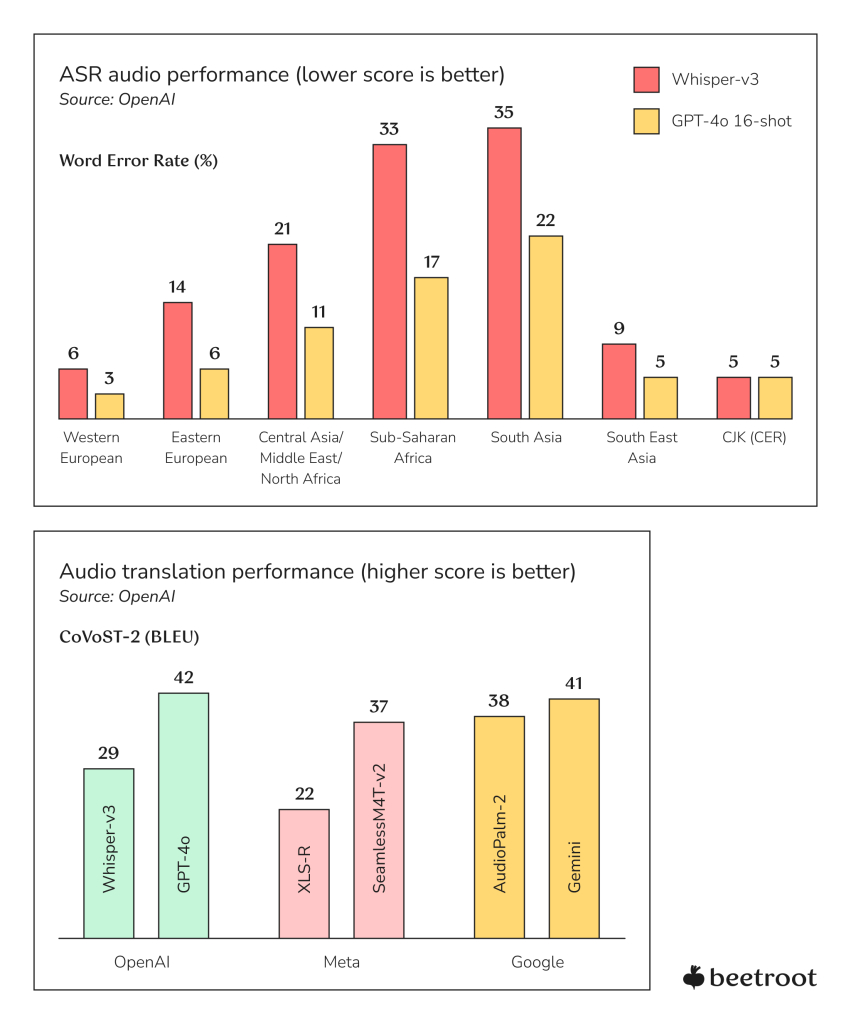
In terms of Automatic Speech Recognition (ASR), OpenAI’s Whisper-v3 demonstrates exceptional performance, achieving particularly low word error rates (WER) in Western European and CJK languages (6% and 5%). While performance varies across regions, Whisper-v3 maintains strong accuracy even in challenging linguistic environments such as South Asia and Sub-Saharan Africa.
Turning to audio translation capabilities, we see a more competitive landscape. The BLEU scores, which measure translation quality (higher is better), reveal that while specialized models like Whisper-v3 excel in specific tasks like ASR, more generalized models such as GPT-4o and Gemini are demonstrating impressive versatility, performing well across both speech recognition and translation tasks.
The strong performance of these AI models in audio processing and translation tasks points to significant advancements in machine understanding of spoken language. This progress has substantial implications for real-time translation, transcription tools, and voice-activated AI assistants. By the way, we leveraged OpenAI’s Whisper for speech recognition in Beetroot’s in-house digital accessibility solution, Speak’N’Hear.
Factors to consider in a back-to-back AI comparison
While there can be many ways to use AI models, one should have a clear understanding of their performance and limitations depending on their task requirements. As these systems are evolving rapidly, there is no straightforward answer to which of them is the best. However, considering several key points can help identify the most suitable option for your needs.
Performance and accuracy
The performance statistics on GPT, Claude, and LLaMA, as well as their competitors, are mostly self-reported, although the values coincide in various sources. Unless you have access to the training datasets and the ability to run models with billions of parameters, LLM benchmarks should be enough to prune the performance index down to a small number of possible choices. Resources like Chatbot Arena (LMSYS) and Open LLM Leaderboard (HuggingFace) provide more statistics, which are updated regularly, to help determine which AI system is best for your scenario.

Safety and data protection
The regulatory baseline, when it comes to AI, is still low. The EU Artificial Intelligence Act can become a global standard in the field of AI regulation. It determines three risk categories: unacceptable (e.g., banning government-run social scoring of the type used in China), high-risk applications (e.g., CV scanning of job applicants) that are subject to specific legal requirements, and all the rest. If the apps are not explicitly banned or listed as high-risk, they are basically not regulated. Sadly, as of now, there are no other options besides taking the words of AI system providers (OpenAI, Anthropic, Google, and their peers) on safety and data privacy.
Model availability and ease of integration
When it comes to availability and model integration, OpenAI’s GPT APIs are currently unmatched. ChatGPT has been the longest in the market, so there is an existing user community and ecosystem of extensions and libraries built around it. Developers can now access GPT-4o in the API as a text and vision model. Claude Opus and Sonnet are available in API, with instant access to these models upon signing up. Depending on the provider, some AI assistants may require a VPN to work in your region.
Scalability and pricing
When choosing AI assistants for businesses, scalability and pricing are crucial, yet there are no “cheap” or “expensive” options to recommend. AI assistants scale to handle increased workloads, with cloud-based solutions often offering better scalability. Pricing models vary widely, including per-user, usage-based, tiered, and custom enterprise-level pricing. Businesses should define their specific use cases, compare pricing models, request demos, consider long-term scalability needs, assess hidden costs, and evaluate ROI to make the best choice.
On a concluding note
AI tools have diverse applications across organizational roles. For C-level executives and management, they’re valuable in communication tasks that require articulate and clear messaging (replying to emails, providing feedback, etc.). In marketing, AI assists with ideation, planning, and content creation. Technical roles benefit from AI in decision-making, problem-solving, trend identification, and information synthesis. Some AI tools are well-suited for helping software developers with coding tasks.
At Beetroot, we are driven by AI’s transformative potential to empower individuals and boost productivity, creativity, and collaboration. By leveraging AI assistants and developing innovative solutions based on AI models, we unlock limitless possibilities for innovation. This approach not only enhances our business operations but also shapes the future of technology and society through our clients’ solutions.
As a tech ecosystem, we also believe in the power of continuous learning and promoting skill development to stay ahead in the tech landscape. Through Beetroot Academy, we provide cutting-edge training programs designed to equip teams with the skills they need to harness AI effectively—whether in engineering, HR, leadership, design, or QA. These programs ensure that businesses are not just keeping up with AI advancements but are leading the way in their respective fields.
Join us to unlock new ways to benefit from AI for the greater good.
Subscribe to blog updates
Get the best new articles in your inbox. Get the lastest content first.
Recent articles from our magazine





Contact Us
Find out how we can help extend your tech team for sustainable growth.
