
Data Pipeline Development Services
Take control of your data through our data pipeline development services. We can help you design and implement efficient data workflows that process information at scale, maintain data integrity, and deliver trusted insights directly to decision-makers.
-
 Top 1%
Top 1%of software development companies on Clutch
-
 EU GDPR
EU GDPRcommitment to security & privacy
-
 60%
60%of business is based on customer referrals
-
 ISO 27001
ISO 27001data security certification by Bureau Veritas
-
 EY EoY 2023
EY EoY 2023EY Entrepreneur of the Year in West Sweden
From Data Silos to Strategic Advantage: The Power of Data Pipelines
Businesses are often inundated with vast amounts of information, yet struggle to extract meaningful information. Effective data pipeline development serves as a bridge between raw data collection and actionable intelligence. While concerns about technical complexity and integration challenges are valid, modern approaches to data pipeline development have dramatically reduced these barriers. Today’s solutions offer flexible, scalable architectures that lay the foundation for future growth.
-
-
Accelerated Decision-Making
Well-designed data pipelines deliver timely, reliable information to decision-makers across your organization. -
Operational Efficiency
Automated data pipelines eliminate manual data processing tasks and free up valuable technical resources to focus on innovation rather than repetitive data management (see more in our robotic process automation services). -
Enhanced Data Quality
Integrated validation, cleansing, and transformation processes ensure that analytics and reporting are based on accurate, consistent information. -
Scalable Growth Foundation
Modern data pipelines are designed to grow with your business, easily accommodating new data sources and increased volumes without requiring complete rebuilds.
-
Our Data Pipeline Services
We architect reliable and efficient data pipelines, empowering your team with smooth data flow and optimized performance across the full spectrum of modern architectures (batch, real-time, and hybrid).
-
Data Ingestion and Extraction
Unify previously isolated data and eliminate blind spots in your decision-making. Our experts connect different data sources, regardless of their format or location. We build connectors and extraction routines to reliably pull your data into the pipeline. We handle everything from structured databases to semi-structured APIs and unstructured data lakes (see more in our database optimization services).
-
Data Transformation and Cleansing (ETL/ELT)
Make confident decisions based on trusted data. We ensure that your data is accurate and consistent. Whether you require traditional ETL or the flexibility of ELT, we apply rigorous data quality checks, cleansing routines, and transformation logic. We can empower you to use data cleansing algorithms to detect and correct inaccuracies, remove duplicates, standardize formats, and handle missing values
-
Pipeline Monitoring and Maintenance
Minimize business disruptions and make sure your data flows remain reliable even as your organization scales. We can help you track pipeline health, performance metrics, and data quality in real time. Our maintenance services include regular optimizations, troubleshooting, and performance tuning so that you are confident your data pipelines continue to meet needs.
-
Data Orchestration
Streamline your data processing and improve operational efficiency with our meticulous coordination. Our data orchestration services automate the execution of your data pipeline workflows. We design and implement orchestration processes that confirm tasks are executed in the correct order, dependencies are managed, and errors are handled effectively.
-
Data Security and Governance
Maintain regulatory compliance and protect sensitive information with appropriate data access. We can integrate enterprise-grade security measures throughout your data pipeline, from source to consumption. Our governance frameworks include data lineage tracking, access controls, and audit capabilities (see more in data science consulting services).
-
Custom Workshops
Equip your team with the knowledge and skills they need to build, manage, and optimize your data pipelines effectively. Whether you’re looking to upskill your team in modern data pipeline architectures, learn new practices for data governance, or master specific tools and technologies, we can design a workshop that delivers practical, hands-on knowledge.
Looking for expert data pipeline guidance?
Cooperation Models
Beyond data pipeline development, we offer a complete spectrum of AI capabilities, from Machine Learning services and MLOps services, extending to NLP services and LLM development services.
-

Dedicated Development Teams
Direct communication and controlWork with professionals who become a fully integrated part of your team. Use this strategy so as to access benefits of sustained tech support and build consistent cooperation with Beetroot. Take responsibility over the project and expand your capabilities at your own pace.
-

Project-Based Engagements
End-to-end supportLean on our end-to-end data & AI services. We bring together specialized experts, including data pipeline engineers and development pipeline consultants. This is the right choice for companies that search for a strategic partner for a long-term perspective.
-

Custom Tech Training
Hands-on team trainingEnroll in our workshops and accelerate your data pipeline development. Drawing upon our network of 400+ experts, we can create workshops that enhance your team’s technical skills. We cover various aspects of the topic and share hands-on experience.
Tools and Technologies
Data pipeline development is all about diverse technologies and tools, each serving specific functions in the creation, management, and optimization of data workflows. They enable efficient data ingestion, transformation, storage, and analysis.
-
Data Ingestion and Extraction
-
 Apache Kafka Connect
Apache Kafka Connect -
 AWS Data Pipeline
AWS Data Pipeline -
 Azure Data Factory
Azure Data Factory -
 Google Cloud Dataflow
Google Cloud Dataflow
-
-
Data Transformation and Processing
-
 Apache Spark
Apache Spark -
 Apache Flink
Apache Flink -
 dbt
dbt -
 SQL
SQL
-
-
Data Orchestration and Workflow Management
-
 Apache Airflow
Apache Airflow -
 Prefect
Prefect -
 Dagster
Dagster -
 AWS Step Functions
AWS Step Functions
-
Data Pipeline vs. ETL Pipeline
While both data pipelines and ETL pipelines facilitate data movement, a modern data pipeline is a broader concept that encompasses real-time streaming and diverse data types. ETL pipelines traditionally focus on batch processing of structured data for data warehousing.
-
Data Pipeline
- Versatile Data Handling. Supports a wide array of data sources and formats.
- Real-Time Processing Capabilities. Enables the continuous flow and transformation of data.
- Scalable and Flexible Architecture. Designed to handle increasing data volumes and new business needs.
-

ETL Pipeline
- Structured Data Focus. Primarily designed for processing and transforming structured data from transactional systems to data warehouses.
- Batch Processing Orientation. Typically operates in batch mode, processing data at scheduled intervals, rather than in real-time.
- Defined Transformation Logic. Employs predefined transformation rules and logic.
Meet Your Team of Data Pipeline Engineers
The power behind our data pipeline development stems from the expertise and dedication of our professionals:
-

$65/h
-
$75/h
-

$60/h
-
$50/h
-

$50
Our Data Pipeline Development Process
We implement a flexible, iterative data pipeline development methodology that is aligned with specific project requirements.
-
Discovery & Requirements Analysis
Our experts analyze your goals, data sources, and technical environment. This foundation ensures we design solutions that address your specific challenges.
-
Architecture Design
Based on requirements gathered, we create an architecture blueprint that outlines the technical components, data flows, and integration points of your pipeline solution (see more in our data annotation services). We share multiple architectural options and help you understand the tradeoffs between different approaches.
-
Prototype Development
We develop a working prototype that demonstrates core functionality with a subset of your data, which allows stakeholders to validate concepts and provide early feedback. The prototype serves as a proof of concept for critical components and helps refine requirements for the complete solution.
-
Iterative Development
Our team builds the complete data pipeline in planned iterations, with each cycle delivering testable components that provide incremental value. We incorporate feedback throughout the development process, making adjustments as needed.
-
Testing & Quality Assurance
Our quality assurance process includes automated testing, load testing, and validation against expected outcomes.
-
Deployment & Integration
Our deployment process includes environment setup, configuration management, and integration with surrounding systems. We implement proper monitoring and logging from day one to guarantee operational visibility and support.
-
Knowledge Transfer and Support
Throughout the project, we offer documentation and training. After deployment, we provide ongoing support to make sure the pipeline continues to perform optimally as your business evolves.
Industries We Cover
Our expertise spans diverse sectors, where efficient data flow is critical for informed decision-making, innovation, and growth. Here are several data pipeline examples:
-
HealthTech
We can design HIPAA-compliant data pipelines that securely integrate electronic health records, medical imaging, wearable device data, and clinical trials information.
-
GreenTech
Our data pipelines support renewable energy optimization, environmental monitoring, and sustainability reporting by integrating IoT sensor networks, satellite imagery, and operational systems
-
EdTech
Our custom solutions can enable educational institutions and EdTech companies to gain deeper insights into learning patterns, optimize curriculum delivery, and improve student outcomes.
-
FinTech
We can help you adopt high-performance data pipelines that meet stringent security and compliance requirements for real-time transaction processing, risk assessment, and fraud detection.
-
Retail
We create unified data ecosystems that integrate online and offline customer interactions, inventory management, and supply chain data.
-
Manufacturing
Our experts design data pipelines that connect production equipment, supply chain systems, and quality assurance processes.
Modernize your data infrastructure with Beetroot:
Why Choose Beetroot as a Data Pipeline Solutions Provider
Gain access to our wealth of IT knowledge, which has fueled the success of 200+ impactful partners in 24 countries.
-
Pipeline Architecture Excellence
Our engineering experts design data pipelines that balance performance, scalability, and maintainability, avoiding the common pitfalls of overly complex or inflexible architectures.
-

End-to-End Data Lifecycle Management
We implement comprehensive solutions that address the entire data journey, from ingestion through processing, storage, and analysis to eventual archiving or deletion.
-

Sustainable Data Processing
We architect energy-efficient data pipelines that minimize computational waste through intelligent workload scheduling and sustainable algorithms.
-
Responsible AI Integration
Our data pipelines incorporate ethical AI practices and governance frameworks that ensure transparent, explainable, and fair use of automated decision systems (check out our GenAI services).
-

Legacy Integration
We connect modern data pipelines with legacy systems that may lack standard APIs. We use historical data alongside new sources without disruptions in operations.
Our Clients Say
Learn why our clients rely on our technical expertise to achieve their business goals.
Beetroot in Action
We’ve delivered successful projects for a variety of clients, from startups to established enterprises. Here are a few examples of the impact we’ve made:

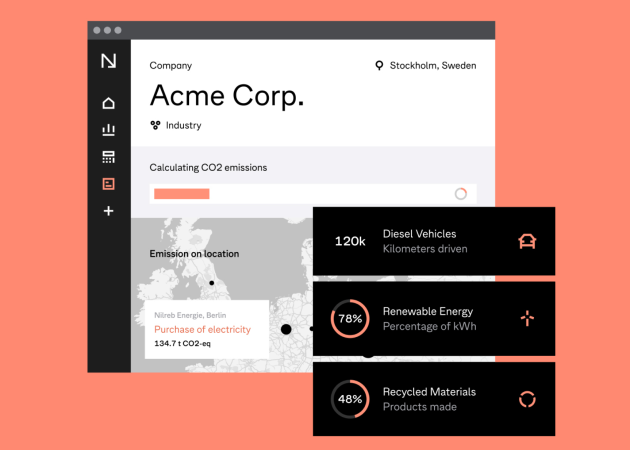

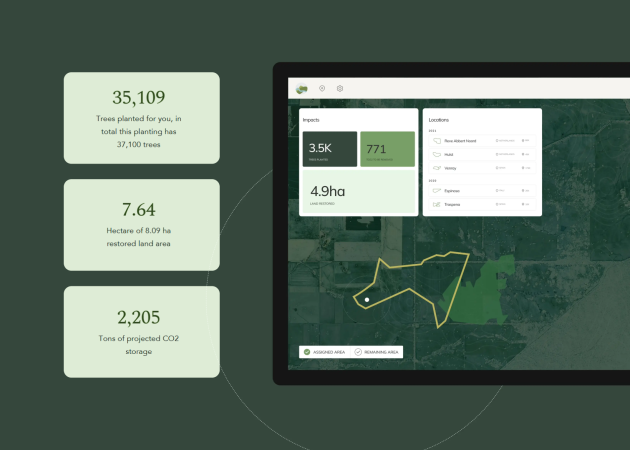

Custom Workshops
We offer focused, practical education in data pipeline development. Our goal is to empower your team to understand, but actively build, manage, and optimize data pipelines. Here’s why investing in custom data pipeline training is crucial:
- Accelerated Skill Development. We focus on practical, hands-on exercises relevant to your team’s day-to-day work.
- Reduced Development Bottlenecks. Our workshops break down development bottlenecks and promote seamless collaboration.
- Improved Problem-Solving. We can incorporate real-world scenarios and troubleshooting exercises into our workshops so that your team has knowledge to tackle various challenges.
Struggling with data silos and inconsistent information?
Our experts can help. Fill out the form to discuss your needs and challenges.

